|
|
Oracle 2017. 10. 18. 14:11
DB Link 설정을 그동안 사용하면서 많이 사용을 안해서 그런지 이런 오류 메세지를 만난적이 없었다.
그러다 오늘 알게되었기에 오라클 문서를 확인하고 기록으로 남기기 위해 작성한다.
ORA-02020 too many database links in use Cause: The current session has exceeded the INIT.ORA open_links maximum.
Action: Increase the open_links limit, or free up some open links by committing or rolling back the transaction and canceling open cursors that reference remote databases.
이런 오류 메시지를 만났다면 Open_links parameter 설정을 확인해주어야 한다는 의미다.
OPEN_LINKSOPEN_LINKS specifies the maximum number of concurrent open connections to remote databases in one session. These connections include database links, as well as external procedures and cartridges, each of which uses a separate process.
출처 : http://docs.oracle.com/cd/E11882_01/server.112/e40402/initparams164.htm#REFRN10138
해당 파라미터의 초기값은 4개이다. 결론부터 얘기하면 DB Link 설정 갯수가 4개보다 많기 때문에 위와 같은 오류 메세지를 보게 되었다는 얘기입니다. 따라서, 추가로 생성해야 하는 상황이라면 이 값을 조정해주시면 됩니다. 위의 설정 값을 확인하기 위해서는 "select name, value from v$parameter where name='open_links'; "와 같은 Query로도 확인이 가능합니다. ( sqlplus에서라면.. show parameter open_links로도 확인 가능) 값의 조정은 init.ora 파일에서 직접해도 되고, "alter system set open_links=10 scope=spfile;" 와 같이 조정해도 됩니다. 값은 필요한 만큼 조정하시되, 위에 보시면 최대 값이 255인것을 감안하시면 됩니다. 값이 조정되었다면 이를 반영하기 위해서는 DBMS를 Restart 시켜주어야 반영됨을 잊지 마세요.
이외에 참고로 DB Link에 연관된 파라미터 정보와 제한 정보는 아래와 같습니다. 참고하시기 바랍니다. dblink Specify the complete or partial name of the database link. If you specify only the database name, then Oracle Database implicitly appends the database domain of the local database. Use only ASCII characters for dblink. Multibyte characters are not supported. The database link name is case insensitive and is stored in uppercase ASCII characters. If you specify the database name as a quoted identifier, then the quotation marks are silently ignored. If the value of the GLOBAL_NAMES initialization parameter is TRUE, then the database link must have the same name as the database to which it connects. If the value of GLOBAL_NAMES is FALSE, and if you have changed the global name of the database, then you can specify the global name. The maximum number of database links that can be open in one session or one instance of an Oracle RAC configuration depends on the value of the OPEN_LINKS and OPEN_LINKS_PER_INSTANCE initialization parameters. Restriction on Creating Database Links You cannot create a database link in another user's schema, and you cannot qualify dblink with the name of a schema. Periods are permitted in names of database links, so Oracle Database interprets the entire name, such as ralph.linktosales, as the name of a database link in your schema rather than as a database link named linktosales in the schema ralph.) |
출처 : http://docs.oracle.com/cd/E11882_01/server.112/e41084/statements_5005.htm#SQLRF01205
Happening 2017. 5. 24. 15:52
MS Outlook 일정과 Google 일정을 동기화 하고 싶다면???
저는 원래 업무 일정을 Google 캘린더에 등록하여 개인적으로 관리해 왔습니다. 팀원과의 일정 공유를 위한 것이 아닌, 순수하게 개인적인 용도였지요.
그런데 최근에 아웃룩으로 일정 관리 및 공유하는 것을 경험하게 되었고 이것을 통해 누가 부재인지, 내가 참석해야 하는 회의는 무엇이 있는지의 확인이 매우 편리해졌습니다. 한가지 단점이 있다면 회사 보안 정책으로 인해 핸드폰에서 사내 서버로의 접근이 불가능하여 PC에서만 일정이 확인 가능하다는 것이었습니다.
여러가지로 방법을 수소문한 결과 Outlook 일정을 Google 계정으로 동기화 하는 Tool이 있다는 것을 알게 되었고 지금은 핸드폰으로 편리하게 일정을 확인하고 알림을 받고 있습니다. 오늘은 Outlook 일정을 Google 계정으로 동기화하는 방법을 공유하도록 하겠습니다.
<동기화 개요> 
제가 기존/현재에 사용중인 일정 동기화 개요입니다. 결론부터 말씀드리면 Outlook에 입력한 일정을 Google 계정으로 동기화 하고 핸드폰에서 Google 계정을 확인하는 방식입니다. Google 계정에 등록된 일정을 핸드폰에서 확인하는 것이므로 핸드폰이 Google 계정과 동기화되어 있어야 합니다. (안드로이드 폰을 사용중이시라면 대부분 구글 계정과 이미 동기화 되어 있을 것이므로 크게 신경쓰지 않아도 될 듯 합니다) 이 글에서 설명하는 것은 Outlook → Google로 동기화이며 Google → Outlook은 포함되어 있지 않으므로 참고하시기 바랍니다.
<GO Contact Sync Mod 다운 및 설치>
Outlook → Google로 동기화를 위해서는 Go Contact Sync Mod라는 Tool이 필요합니다. 아래의 Sourceforge라는 사이트에서 무료로 다운 받습니다.
- 다운 경로 : https://sourceforge.net/projects/googlesyncmod/

설치 방법은 어렵지 않으므로 별도의 설명은 생략합니다.
<실행 및 설정>

Go Contact Sync Mod의 실행 화면입니다. 화면에 표시한 대로 몇가지 설정이 필요합니다. 동기화하고자 하는 Google 계정, 동기화 하고자 하는 항목(연락처, 일정), 동기화 옵션, 동기화 주기를 선택하면 설정된 대로 백그라운드에서 계속 동기화를 진행하여 줍니다.

정상적으로 백그라운드에서 동기화를 진행하고 있는 경우에는 Go Contact Sync Mod가 실행되고 있는 것을 확인할 수 있습니다.
<팀 일정공유 방법 Sample>
1. 아웃룩에서 내 업무 일정 작성합니다 (예. 팀 회의)

2. 회의 참석 인원 대상으로 초대 메일을 발송하여 일정을 공유합니다. 일정 공유 메일을 받으면 내 달력에도 해당 일정이 자동 반영됩니다.

3. 일정을 등록한 사람과 일정 초대를 받은 사람의 Outlook 일정에는 해당 일정이 자동 반영되고 백그라운드에서 열심히 일하고 있는 Go Contact Sync Mod가 정기적으로 Google 계정으로 동기화를 진행합니다. 동기화가 완료되면 이제는 폰에서도 팀 업무일정을 확인 가능합니다.
그럼 이것으로 Go Contact Sync Mod를 이용한 Outlook → Google 일정 동기화 설정 정보공유를 마칩니다. 감사합니다.
출처: http://lifeisb.tistory.com/25 [Let the life be beautiful]
카테고리 없음 2017. 5. 24. 15:19
iTunes에서 iPhone, iPad 또는 iPod을 인식하지 못하는 경우USB 케이블을 사용하여 컴퓨터에 기기를 연결했지만 iTunes가 iPhone, iPad 또는 iPod을 인식하지 못하는 경우 도움을 얻을 수 있습니다. 컴퓨터에서 iTunes가 연결된 기기를 인식하지 못하는 경우 알 수 없는 오류 또는 '0xE' 오류가 표시될 수 있습니다. 이 경우 다음 단계에 따라 각 단계를 수행한 후 기기를 다시 연결해 봅니다. - 컴퓨터에서 사용하고 있는 iTunes가 최신 버전인지 확인합니다.
- Mac 또는 Windows PC에 설치된 소프트웨어가 최신 버전인지 확인합니다.
- 기기가 켜져 있는지 확인합니다.
- "이 컴퓨터를 신뢰하겠습니까?"라는 경고가 표시되면 기기의 잠금을 해제하고 '신뢰'를 탭합니다.
- 사용 중인 기기를 제외하고 모든 USB 액세서리를 컴퓨터에서 뽑습니다. 각 USB 포트를 사용해 보고 작동하는지 확인합니다. 그런 다음 다른 Apple USB 케이블을 사용해 봅니다.
- 컴퓨터와 iPhone, iPad 또는 iPod을 재시동합니다.
- 기기를 다른 컴퓨터에 연결해 봅니다. 다른 컴퓨터에서도 같은 문제가 발생하면 Apple 지원에 문의합니다.
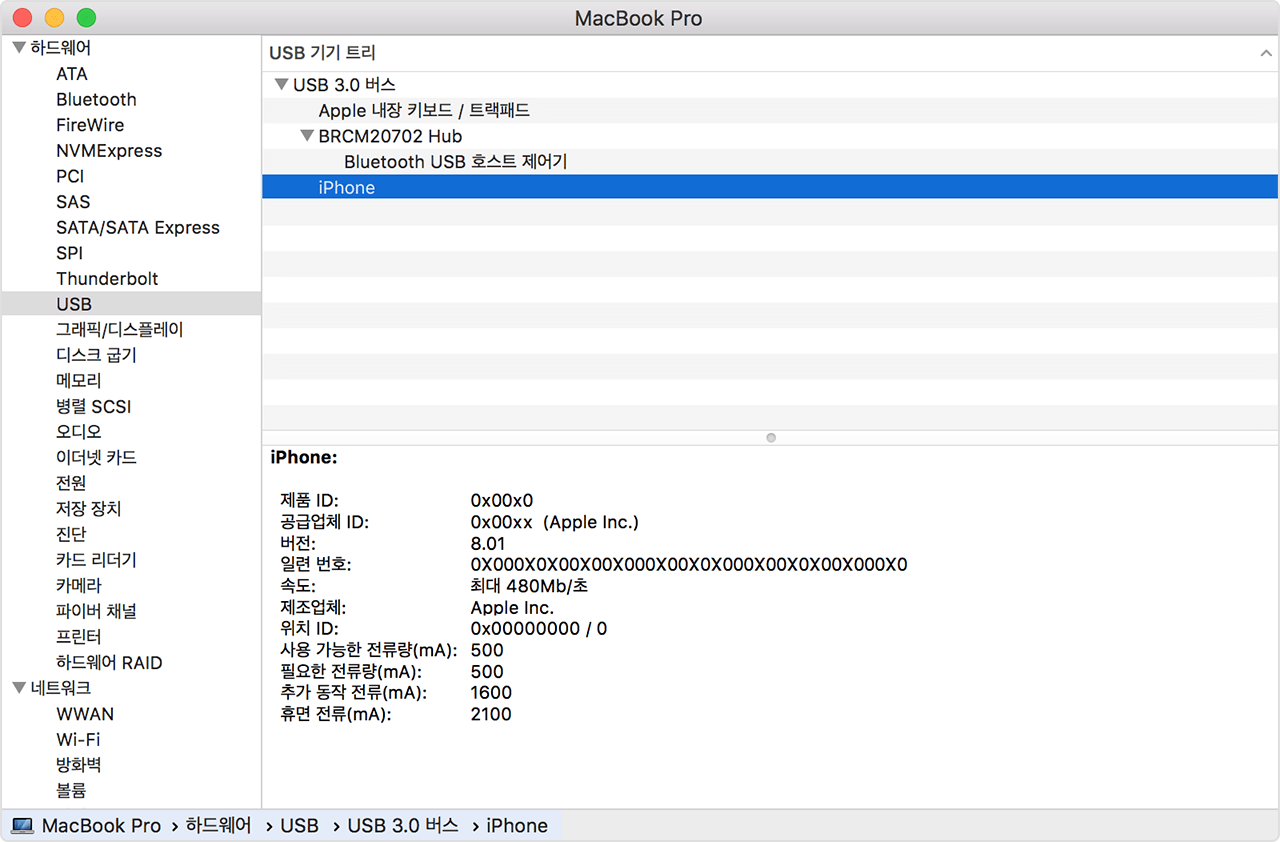
추가 지원이 필요한 경우 Mac 또는 Windows PC에 대한 아래 단계를 따르십시오. Mac을 사용하는 경우- option 키를 누른 상태에서 Apple 메뉴를 클릭한 다음 '시스템 정보' 또는 '시스템 리포트'를 선택합니다.
- 왼쪽의 목록에서 'USB'를 선택합니다.
- USB 기기 트리 아래에 iPhone, iPad 또는 iPod이 표시되는 경우 타사 보안 소프트웨어를 제거합니다. 표시되지 않는 경우 Apple 지원에 문의합니다.

Windows PC를 사용하는 경우다음 단계에 따라 Apple Mobile Device USB Driver를 다시 설치합니다. - 기기를 컴퓨터에서 분리합니다.
- 기기를 다시 연결합니다. iTunes가 열리면 닫습니다.
- 키보드에서 Windows 키와 R 키를 눌러 실행 명령을 엽니다.
- 실행 윈도우에 다음을 입력합니다.
%ProgramFiles%\Common Files\Apple\Mobile Device Support\Drivers - '확인'을 클릭합니다.
usbaapl64.inf 또는 usbaapl.inf 파일을 마우스 오른쪽 버튼으로 클릭하고 '설치'를 선택합니다.
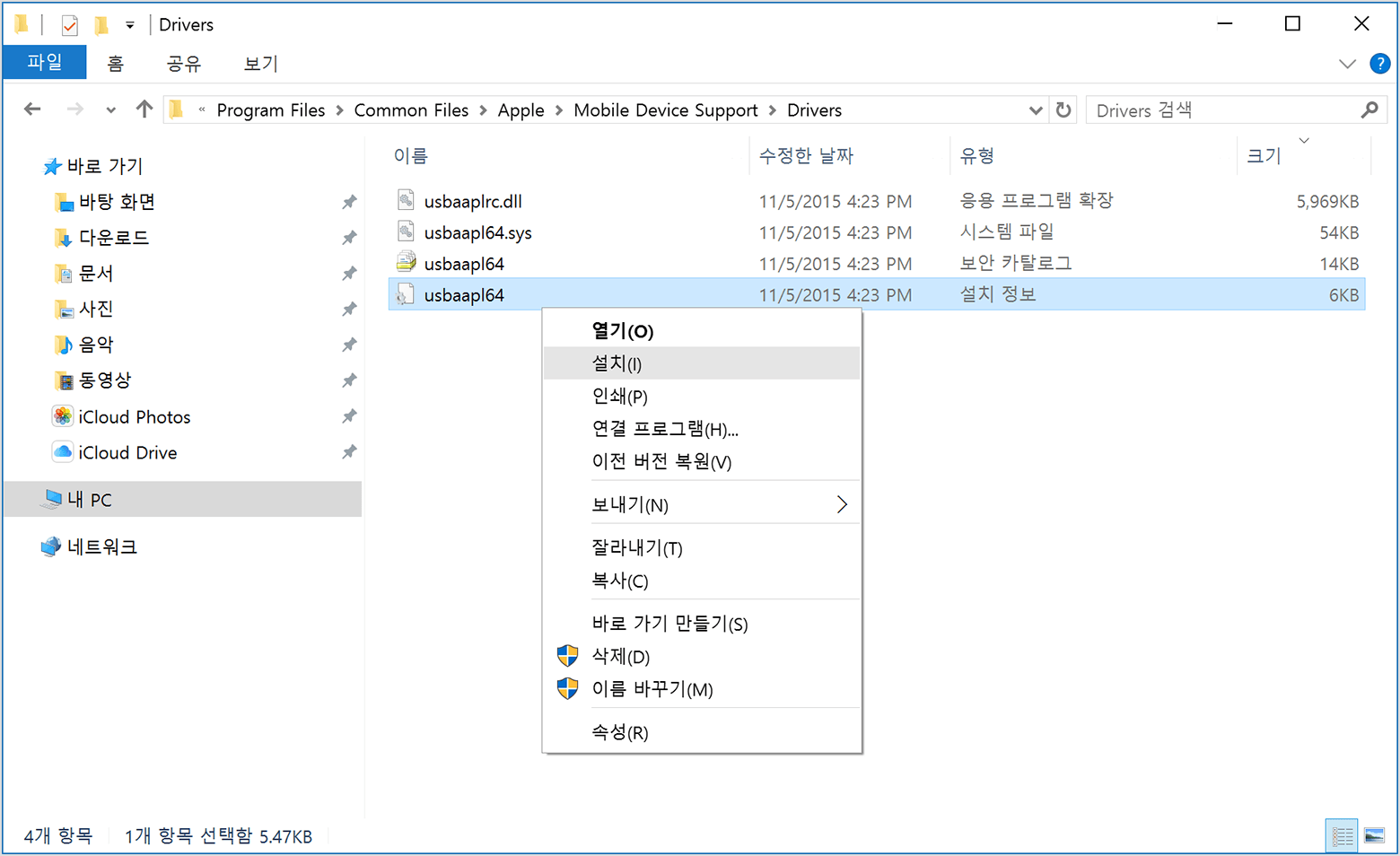
usbaapl64 또는 usbaapl로 시작하는 다른 파일이 표시될 수도 있습니다. .inf로 끝나는 파일을 설치해야 합니다. 어떤 파일을 설치해야 하는지 잘 모르겠으면 파일 탐색기 윈도우에서 빈 영역을 마우스 오른쪽 버튼으로 클릭하고 '보기'를 클릭한 다음, '세부 정보'를 클릭하여 올바른 파일 유형을 찾습니다. 설치하려는 파일은 설치 정보 파일입니다.- 기기를 컴퓨터에서 분리한 다음 컴퓨터를 재시동합니다.
- 기기를 다시 연결하고 iTunes를 엽니다.
기기가 여전히 인식되지 않는 경우장치 관리자에서 Apple Mobile Device USB Driver가 설치되어 있는지 확인합니다. 다음 단계에 따라 장치 관리자를 엽니다. - 키보드에서 Windows 키와 R 키를 눌러 실행 명령을 엽니다.
- 실행 윈도우에
devmgmt.msc를 입력한 다음 '확인'을 클릭합니다. 장치 관리자가 열립니다. - 범용 직렬 버스 컨트롤러 섹션을 찾아 확장합니다.
- Apple Mobile Device USB Driver를 찾습니다.
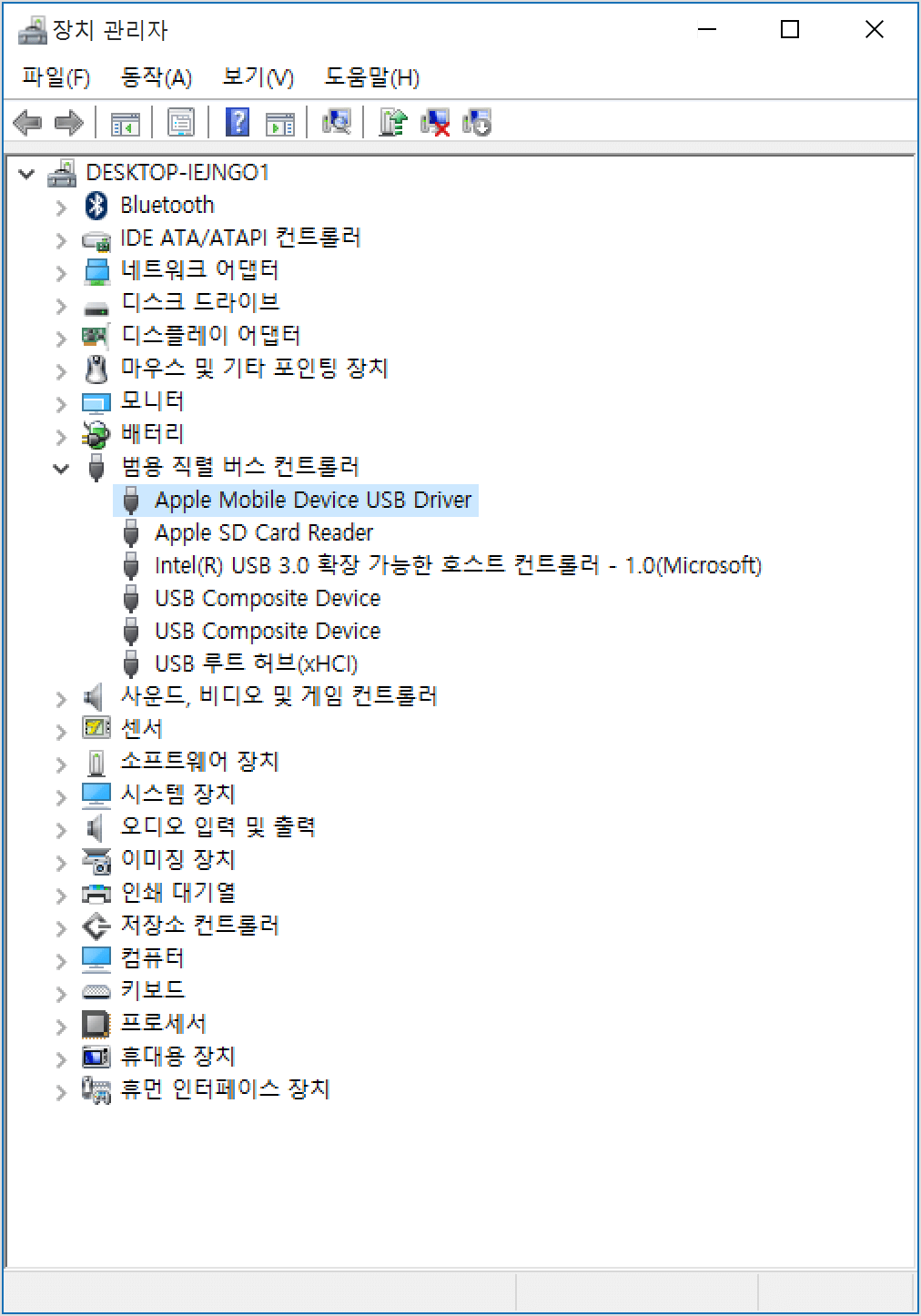
Apple Mobile Device USB Driver가 표시되지 않거나 알 수 없는 장치가 표시되는 경우:- 다른 USB 케이블을 사용하여 기기를 컴퓨터에 연결합니다.
- 기기를 다른 컴퓨터에 연결합니다. 다른 컴퓨터에서도 같은 문제가 발생하면 Apple 지원에 문의합니다.
Happening 2016. 2. 22. 10:46
아래의 문장을 읽으시고 해당된다 2점 애매하다 1점 해당 되지않는다 1점 으로 계산하시고 마지막에 합계를 내주세요
□ 01. 어떤 일이라도 신중을 기한다. □ 02. 인터넷이나 게임을 하면 시간을 잊어버린다. □ 03. 멍때리고 텔레비를 보는 경우가 많다. □ 04. 손님이 나란이 줄을 서있는 가게를 좋아한다. □ 05. 컴퓨터가 오랜된것이라도 소중히 사용한다.
□ 06. 업무 도구에는 얽매이지 않는다.
□ 07. 사생활보다 일이 먼저다. □ 08. 아침은 아슬아슬할때까지 자고 일어난다. □ 09. 밤늦게 잔다. □ 10. 한번더 자는경우가 많다.
□ 11. 휴일에도 일생각을 한다. □ 12. 휴일에는 느긋하게 자고있다.
□ 13. 몸을 단련하는일을 그다지 하지 않는다. □ 14. 장래의 목표를 가지고 있지 않다. □ 15. 미래보다도 현재가 소중하다라고 생각한다.
□ 16. 시킨거밖에 일하지 않는다. □ 17. 시급보다는 년봉을 생각한다. □ 18. 가능한한 잔업수당을 벌고싶다. □ 19. 다른사람 말은 순순히 듣는다. □ 20. 주변 사람들에 맞춰서 행동한다.
□ 21. 복수의 일을 병행해서 진행한다. □ 22. 업무 순서를 확실히 정하고 일을 시작한다. □ 23. 중요한 일보다 긴급한일을 우선적으로 한다. □ 24. 귀찮은 일은 나중에한다. □ 25. 일의 단락을 지을때 까지는 퇴근하지 않는다.
□ 26. 지시받은 일은 곧바로 한다. □ 27. 업무를 완벽하게 하지않으면 기분이 내키지 않는다. □ 28. 사고방식, 업무의 진행방법은 보수적이다. □ 29. 일은 가능한한 혼자서 한다. □ 30. 문장을 쓰는게 서툴다
□ 31. 헛된 일은 하고 싶지않다.
□ 32. 주위에 신경을 쓰는 경우가 많다. □ 33. 어떤일이라도 거절 않한다. □ 34. 다른사람이 자신을 어떻게 생각하고 있는지 신경쓰인다. □ 35. 돈과 시간중에 돈이 더 소중하다.
결과
40~70점
당신은 일처리가 느린 사람입니다. 일에 대한 사고방식, 생활 습관등을 새로 검토해야될 필요성이 있는것 같습니다.
15~39점 당신은 평범한 사람입니다. 조금은 일에 대한 자세를 바꾸면, 업무 능력이 한단계 업 될수있습니다.
0~14점
당신은 일처리가 빠른 사람입니다. 일 뿐만아니라 사생활에서도 충족한 생활을 보내고 있을 것입니다.
일처리가 빠른 사람의 사고방식■ 완벽하지 않아도 좋다라고 생각한다. ■ 필요 이상 신경 쓰지않는다. ■ 다른 사람과 다르게 행동한다. ■ 때와 경우에 따라서는 일을 거절한다. ■ 시킨 일만 하지마라. ■ 옛날 방식에 고집하지 않는다. ■ 확실한 목표를 가진다. ■ 미래를 생각해서 일한다. ■ 결과를 신경쓰지말고 할수 있는일을 힘껏 한다
일처리가 빠른 사람의 업무방식
■ 회사 이외에서도 일을 할수있다.
■ ON 과 OFF를 확실히 한다.(일을할땐 일을 놀땐 논다)
■ 하나의 일에 집중해서 완성시킨다.
■ 일의 순서에 너무 고집 부리지 않는다.
■ 급하지 않는 일을 중시여긴다.
■ 않해야할 업무 리스를 만든다.
■ 시간 먹는 벌레를 발견하면 즉시 처리한다.
■ 뭐든 노트에 뭐든 기록한다.
■ 메뉴얼과 체크리스트를 활용한다 ■ 근무 시간을 멍하니 보내지 않는다. ■ 일이 끝난후의 시간을 자신의 투자에 사용한다. ■ 퇴근 시간을 결정해서 일을한다. ■ 투자효과를 생각해서 시간을 사용한다. ■ 단기투자 보다 장기 투자를 선택해라. ■ 시간을 2배로 활용한다.(이동 시간등)
일처리가 빠른 사람의 생활습관■ 지금밖에 할수없는 일은 지금한다.
■ 필요없는 물건은 눈 딱감고 버린다. ■ 매일 운동을 한다.(체력)
■ 돈으로 시간을 산다.(100m 떨어진곳에서 100원에 파는 물건이 1m 떨어진 곳에서 200원에 판다면 200원 짜리 물건을 사란소리) ■ 업무의 도구에 고집한다.(사용 하기 편한 펜, 노트 등등) ■ 사생활 시간을 충분히 확보 한다. ■ 집중력을 높인다.(충분히 자라)
■ 작업을 시작하기전에 어떤식으로 하면 효율적으로 할수 있을지 생각하고 작업하기. ■ 뇌의 골든타임을 유용하게 활용한다.(아침에 공부) ■ 무리를 해서라도 아침 일찍일어나 본다.(잠자는 시간을 활용한다) ■ 자고 일어나 다시 자는건 하지말고, 낮잠을 잔다. ■ 자기전에 몇시간 잘수있을지 생각한다. ■ 휴일에도 생활리듬을 뿌수지 않는다. ■ 인생의 시간을 관리해서 자신의 목표에 접근한다.(뭐를 하기 위해서, 몇살에 뭐가 필요한지)
출처 : http://tkdwnsdkk.tistory.com/99
IT News 2016. 2. 22. 10:41
vim가 있으면 대부분의 프로그래밍이 가능하다. vim습득 하는데 시간이 걸린다는게 안좋은점이다. 에이터 플러그인 - neocomplcache.vim
- quickrun.vim
- vimproc + quickrun
- unite.vim
MacVimEmacsVIM, Emacs는 특별 하다라는 느낌이네요 에디터 플러그인 CocoaEmacsMouMarkdown를 쓰기위한 에디터 SublimeText2CotEditor무료. 완전 가벼운 에디터.
간단한 문장 수정에 적합하다. Coda쉐어. 에디터+IDE 같은 느낌. 디자인을 확인하면서 편집이 가능하다.FTP,SSH,SVN등도 함께 쓸수 있어서 디자이너에게는 이걸로 충분. TextWranglerEspressoEspresso 는 리얼타임으로 CSS를 프리뷰하면서 쓸수 있는 에디터. JSON Editor간단하게 JSON을 조작하는 에디터.
IDE(종합개발환경)XcodeiPhone어플을 개발할 마음이 없어도 넣어두면, 서로 차이가 나는 소스를 간단하게 다룰수 있는 FileMerge어플이랑opendiff코멘드등 덤으로 붙어 있기 때문에 추천 EclipseEclipse나NetBeans등 우선 사용하는 파. 그래서 어느쪽이 좋은지를 결정하는거보다 '이건 뭐가 뛰어나지?'를 보고, 경우에 따라서 바꿔 가며 쓰자. http://www.eclipse.org/ NetBeansEclipse나NetBeans등 우선 사용하는 파. 그래서 어느쪽이 좋은지를 결정하는거보다 '이건 뭐가 뛰어나지?'를 보고, 경우에 따라서 바꿔 가며 쓰자. PhpStromPHP나JavaScript를 시작하는 웹 프로그래머용 IDE。 Cloud9아직 조잡하지만, 브라우저에서 실행할수 있는IDE. GitHub나Bitbucket등과 연동 WebStorm현재 IDE중에서는 JavaScript 부분의환경이 최고. 자매품 PHPStorm도 평가가 좋다,
내부 소스 프로그램 수정,버그 수정등이 간단하게 되지만, 유료 입니다. 써볼만한 가치는 있다고 생가갑니다... Nidenode.js IDE
SQL, DBSequel Pro MySQL클라이언트. phpMyAdmin가 필요없어 졌다. NavicatMySQL클라이언트 MySQLWorkbenchEER그림도 그릴수 있기때문에 데이터 베이스 설계에도 사용할수있음. HeidiSQLWindows용 MySQL클라이언트 인데요,HeidiSQL
JDBC/ODBC등없이 이거 하나로 접속 가능하며, 스프레드 시트를 순차적으로 열어가는 형태의 브라우징이 가능하다. 그렇기 때문에 "실제 DB데이터를 보면서 데이터를 조작한다" 라는 점이 직감적으로 가능해, 매우 편리. SSH터널 접속, 서버 간의 데이터 덤프 & 리스토어도 가능하기 때문에 , 운영 작업은 거의 이걸로 완결.
단, 좀 불안정하기 때문에 , 거의 멈추지 않는 작업에는 적합하지 않을지도...
(그런건 서버에서 해! 라고 한소리 들을것 같네요) adminerphpMyAdmin랑 같은 브라우저 베이스의 DB클라이언트. 1파일에서php가 움직이는 환경이라면 OK, 무엇보다도 가볍기 때문에 편하게 자주 쓰고 있다.
MySQL,PostgreSQL, SQLite, MS SQL,Oracle랑 의외로 무슨 SQL이든 사용이 가능한데 어째서인지 마이너. SQLEditorER도 작성 툴. 생SQL나ActiveRecord Model를 출력할수있다. Base.appSQlite용 GUI관리 툴. ERMasterDB관리 툴。
Eclipse의 플러그인인데, DB관리+도큐멘트화가 엄청나게 편해진다. The SQLite SorcererSQLite용 클라이언트. AIR제. PHPMAMP xhprofphp 로 쓰여진 Web어플리케이션 병목지점을 조사할때 필수 xdebugPHPUnit사용할수 있는 테스트 프레임 워크가 이것 밖에 없음 Phingphp 의 빌드 툴,테스트 환경이나 본방 환경등의 환경을 환경채로 부트스트랩 지시나, 종합 테스트 설정에 쓰임
RubytravisCI 계속 통합 bundler어플리케이션 마다 필요한 Gem 을 관리 할수있다. 디플로이 장소 구축에 편리 Capistrano디플로이,PHP 든지 다르 언어로 쓰여진 어플리 케이션도 설정에 따라서 이걸로 디플로이 가능 Pryirb에서 갈아 탐. watchrguardgist
JavaJavaDecompilerJavaScriptnode.jsJavaScript의 대화 실행 환경, 어쨋든 빠르게 JS의 동작 체크 하고싶을때 편리 SpiderMonkeyJavaScript의대화 실행 환경 어쨋든 빠르게 JS동작을 체크하고 싶을때 ringo.jsJavaScript의대화 실행 환경 어쨋든 빠르게 JS동작을 체크하고 싶을때 jsPerfJavaScript의 벤치 마크를 얻을수 있는 사이트. js 벤치마크를 얻어서 공개하는데 편리. jsFiddle브라우저내에서 JavaScript 실행・HTML/CSS의 마크업 같은게 가능하다 Google Closure CompilerJavaScript를 압축할 일이 있으면 、Google Closure Compiler YUI CompressorJavaScript도 CSS도 압축할 일이 있으면 、YUI Compressor impress.jsenchant.jsnpmforevercoffee-scriptrvmnvmnavePythonpypypython에서 쓴 프로그램이 좀 느리다고 생각하면 일단 한번 사용해 본다(django가 움직이기 때문에 관계가 있지요?) virtualenv, virtualenvwrapper, pythonbrewpython이라 하면 virtualenv, virtualenvwrapper。최근에는 pythonbrew을 쓴다 SimpleHTTPServerPython라면、SimpleHTTPServer가 편한거 같습니다. pipipythonscipywerkzeugCSS, HTML, LESSLess.appLESS을 쓸일이 있으면 LESS.app도 편리함. Twitter Bootstrap자신은 프로그램에 집중 하고싶다, 나름대로 멋도 있는게 좋다 라는 경우에는 Twitter Bootstrap로 템플릿을 간단하게 작생해 두면 좋을지도. zen-codingHTML/CSS의 입력 지원. IDE가 지원 하거나、에디터에 플러그인으로 넣을수 있다.
테스트xUnit계XUnitTestPatterns든지 읽어두면 어느 언어의 xUnit계의 테스트 프레임 워크도 이해하기 쉬워짐 xSpec계JBehave이나 RSpec이나. PHP에는 없음.Wikipedia영어판BDD가 알기 쉽다. QuickCheck계프로그램 구조 그대로 기술해서,랜덤으로 인수를 부여서해서 검증하는 테스트 프레임 워크.
오리지널은 Haskell부터인데,메이저 언어 에서도 이미 꽤 사용중.
Haskell 이외의 언어에서 의욕적으로 쓸수있도록 개발하고있는YelloSoft 가 알기 쉬울지도
네트워크Hosterhosts파일을 GUI로 설정하는 어플. wiresharkwireshark, tshark는 사용방법만 외워두면 초 강력. HTTP ClientMockSMTP가상 로컬SMTP. 인터넷에 연결되지 않아도 SMTP로 동작을 체크가능 FTP, SSH, SCP~/.ssh/config: SSH주변 설정을 정리해두면 엄청 편리PuTTYWindowsのSSH는 PuTTY파 이지만、다른 사람에게 추천하는건 Poderosa PoderosaWindowsのSSH는 PuTTY파 이지만、다른 사람에게 추천하는건 Poderosa ClusterSSHTransmit리모트 한 상태에서 파일을 더블 클릭하면 파일을 로컬에 보존→열림、파일 보존→자동적으로 업로드등이 가능, 간단한 개발에는 꽤 편리. 그리고 접속 하는쪽 디렉토리를 Finder에 마운트 할수있는 공포의 기능등. 물론 ssh도 대응 greprakRuby계의 툴 rak 코멘드. grep검색 툴. ackbetter than grep jvgrep자화자찬 인데요,grep로jvgrep. go언어로 쓰여져 있기때문에 linux에서도 windows에서도 똑같이 동작.
일본어 엔코딩은 거의 지원해주고 있고, 여러가지 엔코딩 파일이 섞여있을때의 grep등, 통칭 쓸때없는 문자를 포함한 정규표현에도 올바르게 움직입니다.(한국어도 있나 싶어서 검색해봤지만 딱히 눈에 띄이진 ㅇ Tipsexport GREP_OPTIONS='--color=auto'
에서fgrep/egrep/grep했을때에 매치했을때 단어가 컬러로 하이라이트 되도록 표시 된다 grep/fgrep/egrepの-o 옵션. 매치한 단어만 유출 할수있다, 이것은 한줄로 완성된 프로그램을 쓸때 사용할수 있다.egrep은 확장정규표현 이기때문에 Perl이든지 Ruby같은 편리한 정규표현을 사용할수있다. fgrep은 고정 문자열검색할때 빠른다.
詳細: http://d.hatena.ne.jp/lurker/20070131/1170201200 통계처리수만건 정도의 로그를 간단하게 처리하고 싶을때 편리
중앙값, 표준편차등도 한방에 구할수 있다. 데이터를 기준으로 히스토그램, 3D그래프등 ROctave터미널TotalTerminalMac의 터미너를 바로가기키로 바로 불러낼수 있습니다. iTerm2percolpercol 가 터미널로 사용할수 있는 범용적이고 편리한 툴입니다. 어떻게 사용하는지에 따라 지식/센스등을 시험받는 기분이 듭니다.
SubversionCornerstoneSVN클라이언트 VersionsSVN클라이언트 gitSmartGit (Windows)Git 클라이언트 SourceTree (Mac)Git 클라이언트 GitHub자신이 쓴 소스코드를 공개 tiggit를 사용할거라면 tig가 없으면 살아갈수없다. GitXTowergithub for mac브라우저SRWare IronUserAgent를 바꿀수있는 Chrome같은 사용방법으로 쓸수있다.
패키지관리MacPorts프리. 패키지 관리 툴. 컴파일에 시간이 걸리지만 옛날부터 사용하고 있기떄문에 손 놓을수 없는 툴. HomebrewUNIX의 코멘드등을 간단하게 사용할수 있다. 그외 개발 툴codekitCodeKit automatically compiles Less, Sass, Stylus, CoffeeScript & Haml files. pandoc적으면서 모은 markdown메모를
도큐멘트로 만들때에 pandoc을 사용해서html화 한다. Integrity고속 링크체커. 디플로이 전의 필수 아이템 Omnigraffle쉐어 . 도큐멘트 작성 툴. 이걸로 사용서를 만들때 엄청 빠르게 끝낼수 있음. osx-gcc-installerMac에서「xcode는 필요없지만, gcc만은 원해」라고 생각했을때 죽을만큼 고마운 툴. 우선 Watch 나 즐찾 VMware + Gentoo (or Ubuntu, Debian, etc)ImageOptim이미지 파일을 경량화 HTML서버로서의 DropboxHTML+CSS+JS를 글로벌 액세스로 디버그 할려고 생각하면, 결국 Dropbox의Public 폴더가 가장 간단한 하다는걸 깨달았습니다.(스마트폰용 사이트 등) 그외 작업 효율화 관계 툴CaffeineBetterTouchToolClipMenuLimechat for mac osxPreferences -> Log -> Show image links in inline을 사용함으로 바꾸면
유저명에 대응한 영상을 Twitter에서 가져와서 인라인으로 전개해준다.
물론 틀린 프로필 이미지가 전개 되는경우도 있지만, 유명한 사람이 많은IRC같은거라면 대체로 맞다 QuickSilverQuicksilverは、어플리케이션을 실행시켜、컴퓨터 ・파일조작、e-mail 임시저장과 송신과 같은 작업을 키보드로 빠르게 처리 할수있다. Quixquix 편리하지만 사용하는 사람을 본적이없다. SkitchLingon프리 or 쉐어。자동 기동 관리 툴. OSX의 자동기동 프로그램을 시각적으로 편집하거나 할수있다. Growl기본적인 곳의 Mac이라면 Growl AlfredQuickSilver같은 fuzzy 같은 문자열에 의한、어플리케이션 검색 & 실행 런처. QuickSilver보다도 좋은점은、매치 하는 어플리케이션가 없을때는 구글 검색해준다는 점. ReederRSS리더는 Reeder를 추천. CinchMac에서 간단하게 가면을 2분할(Win7의 그것)을 해주는 툴. FluidWeb어플을 간단하게 로컬어플리화 할수있는 녀석. Web어플로 간단하게 개발해서、클라이언트를 브라우저로 하지 않거나 항상 상주 시키고 싶을때에 편리. DIVVY화면을 핫키 한방에 분할 할수있다. A Better Finder RenameRENAME가 초 간단 Skim경량 PDF리더。Adobe Acrobat보다 좋은거같다. BeanMicrosoft Word보다도 쾌적 Unix/Linux/Macコマンド- gdb
- lv
- xargs
- iotop
- htop
- iperf
- htop
- zsh
- tree
- make
- bison
- awk
서버에서 장기간 걸리는 작업을 불안정한 회선등으로 할때에 특별히 도움이 됩니다. screen은 간단하게 프로센스를 오래 살도록 하는데에 편리합니다.
ssh에서 접속해서 무언가 시간이 걸리는 프로세스를 실행해도 접속을 끊으면 프로세스도 커널에 종료되어버리는데
거기에서 screen안에서 프로세스를 기동해서、screen을 deattached해두면、그 프로세스는 오래살수있도록 할수있습니다.
. 처음에 고맙다라고 생각한게 서버위에서 장시간 작업할때
통신가 툭 끊어져도 screen의 프로세스 자체는 살아남기 때문에, 다시한번 서버에 접속해서
남아있는 screen의 프로세스에 attached하면 작업이 즉시 재개 시킬수 있습니다. vim의 작업 상태 등도 그대로 남아 있습니다.
byobu라는것은 screen가 좋은느낌으로 커스텀마이즈 된 녀석
screen/tmux 가 다가가기 힘든 사람에게는 byobu가 추천입니다.
우선 곤란해 하지 않을 설정이 기본적으로 되어져 있습니다.
나머지는 밑의 많은t ips
"terminal multiplexor Advent Calendar 2011 : ATND" http://atnd.org/events/22320 . 네이티브의 바이너리 관련、od,file,nm,strings,strace,varglind
. 개인적으로는 vim/zsh/screen。이 3개는 어떤 환경이라도 반드시 넣는다
. find ./ -name *.php | xargs grep hoge とかはよく使いますね。Windowsは秀丸のgrepが強力です。
git, 자주 사용하는 코멘드랑 옵션http://qiita.com/items/2047#comment-2182 추운날에 CPU가 발열해서 따듯해지는 코멘드추운날은 충전중의 맥북에서 ruby -r digest/sha1 -e 'loop{Digest::SHA1.hexdigest(Time.now.to_f.to_s)}'
같은걸 하면 잠깐 방치하면 마음대로 CPU가 발연해서 따듯해짐 미분류mscgensequence도를 쓸거라면 mscgen를 추천
cheatyUMLUML을 그리고 출력할수 있는 Web서비스. 유닉크한 URL가 발행되기 때문에 블로그에 붙이거나 가능 클래스 /액티비티 /유즈 케이스 WebSequenceDiagrams.comUML을 그리고 출력할수 있는 Web서비스. 유닉크한 URL가 발행되기 때문에 블로그에 붙이거나 가능 시퀀스 도 http://www.websequencediagrams.com/ CacooAppleK for VMwareMac에서 가상 머신 위의 Windows를 사용하는 경우에는 키 조작이 Mac과 같으되도록 설정해주는 어플. 유료지만 VM위에서의 작업효율이 크게 올라가기 때문에 추천
- VMWare용
http://www.trinityworks.co.jp/software/AppleKforVMware3/index.php
- Parallels용
http://www.trinityworks.co.jp/software/AppleKforParallels3/index.php KeyRemap4Macbook왜인지 아직 거론되지 않는 KeyRemap4Macbook. 키 분배를 자유럽게 커스텀마이즈 할수있음、같은 키를 길게 눌렀을때나 키가 입력되기전까지 기다리는 시간을 표준 보다 고속화 할수있다. Mac을 사용하는 프로그래머에게 있어선 많이 쓰는 어플.
http://pqrs.org/macosx/keyremap4macbook/index.html.ja BitNami다양한 OSS플랫폼/어플을 인스톨러를 사용해서 간단하게 도입할수 있게해주는 소프트 http://bitnami.org/stacks AMPPS다양한 OSS플랫폼/어플을 인스톨러를 사용해서 간단하게 도입할수 있게해주는 소프트
http://www.ampps.com/ TEKICO일본어・영문자 더미 문자를 생각하는 AIR제품 소프트. Web사이트의 프론트 타이프 작업할때에 활용.
출처 : http://tkdwnsdkk.tistory.com/101
IT News 2016. 2. 16. 13:23
그 동안 제 블로그에서 많이 인용되는 글 중 하나가 바로 "쉽게 배우는 하둡 에코 시스템(http://blrunner.com/18)"인데요. 작성한 지 3년이 넘어가는 글이라서 최근 동향에 맞게 다시 정리를 해봤습니다. 
[그림]하둡 에코시스템
코디네이터
- Zookeeper(http://zookeeper.apache.org)
분산 환경에서 서버 간의 상호 조정이 필요한 다양한 서비스를 제공하는 시스템으로, 크게 다음과 같은 네 가지 역할을 수행합니다. 첫째, 하나의 서버에만 서비스가 집중되지 않게 서비스를 알맞게 분산해 동시에 처리하게 해줍니다. 둘째, 하나의 서버에서 처리한 결과를 다른 서버와도 동기화해서 데이터의 안정성을 보장합니다. 셋째, 운영(active) 서버에 문제가 발생해서 서비스를 제공할 수 없을 경우, 다른 대기 중인 서버를 운영 서버로 바꿔서 서비스가 중지 없이 제공되게 합니다. 넷째, 분산 환경을 구성하는 서버의 환경설정을 통합적으로 관리합니다.
리소스 관리
- YARN(http://hadoop.apache.org) 얀(YARN)은 데이터 처리 작업을 실행하기 위한 클러스터 자원(CPU, 메모리, 디스크등)과 스케쥴링을 위한 프레임워크입니다. 기존 하둡의 데이터 처리 프레임워크인 맵리듀스의 단점을 극복하기 위해서 시작된 프로젝트이며, 하둡2.0부터 이용이 가능합니다. 맵리듀스, 하이브, 임팔라, 타조, 스파크 등 다양한 애플리케이션들은 얀에서 리소스를 할당받아서, 작업을 실행하게 됩니다. 얀에 대한 자세한 설명은 http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/index.html을 참고하시기 바랍니다.
- Mesos(http://mesos.apache.org) 메소스(Mesos)는 클라우드 인프라스트럭처 및 컴퓨팅 엔진의 다양한 자원(CPU, 메모리, 디스크)을 통합적으로 관리할 수 있도록 만든 자원 관리 프로젝트입니다. 메소스는 2009년 버클리 대학에서 Nexus 라는 이름으로 시작된 프로젝트이며, 2011년 메소스라는 이름으로 변경됐으며, 현재는 아파치 탑레벨 프로젝트로 진행중이며, 페이스북, 에어비엔비, 트위터, 이베이 등 다양한 글로벌 기업들이 메소스로 클러스터 자원을 관리하고 있습니다. 메소스는 클러스터링 환경에서 동적으로 자원을 할당하고 격리해주는 매커니즘을 제공하며, 이를 통해 분산 환경에서 작업 실행을 최적화시킬 수 있습니다. 1만대 이상의 노드에도 대응이 가능하며, 웹 기반의 UI, 자바, C++, 파이썬 API를 제공합니다. 하둡, 스파크(Spark), 스톰(Storm), 엘라스틱 서치(Elastic Search), 카산드라(Cassandra), 젠킨스(Jenkins) 등 다양한 애플리케이션을 메소스에서 실행할 수 있습니다.
데이터 저장
- HBase(http://hbase.apache.org)
H베이스(HBase)는 HDFS 기반의 칼럼 기반 데이터베이스입니다. 구글의 빅테이블(BigTable) 논문을 기반으로 개발됐습니다. 실시간 랜덤 조회 및 업데이트가 가능하며, 각 프로세스는 개인의 데이터를 비동기적으로 업데이트할 수 있습니다. 단, 맵리듀스는 일괄 처리 방식으로 수행됩니다. 트위터, 야후!, 어도비 같은 해외 업체에서 사용하고 있으며, 국내에서는 2012년 네이버가 모바일 메신저인 라인에 HBase를 적용한 시스템 아키텍처를 발표했습니다.
- Kudu(http://getkudu.io) 쿠두(Kudu)는 컬럼 기반의 스토리지로서, 특정 컬럼에 대한 데이터 읽기를 고속화할 수 있습니다. 물론 기존에도 HDFS에서도 파케이(Parquet), RC, ORC와 같은 파일 포맷을 사용하면 컬럼 기반으로 데이터를 저장할 수 있지만, HDFS 자체가 온라인 데이터 처리에 적합하지 않다는 약점이 있었습니다. 그리고 HDFS 기반으로 온라인 처리가 가능한 H베이스의 경우, 데이터 분석 처리가 느리다는 단점이 있었습니다. 쿠두는 이러한 문제점들을 보완하여 개발한 컬럼 기반 스토리지이며, 데이터의 발생부터 분석까지의 시간을 단축시킬 수 있습니다. 클라우데라에서 시작된 프로젝트이며, 2015년말 아파치 재단의 인큐베이션 프로젝트로 선정됐습니다.
데이터 수집
- Chukwa(http://chukwa.apache.org)
척와(Chuckwa)는 분산 환경에서 생성되는 데이터를 HDFS에 안정적으로 저장하는 플랫폼입니다. 분산된 각 서버에서 에이전트(agent)를 실행하고, 콜렉터(collector)가 에이전트로부터 데이터를 받아 HDFS에 저장합니다. 콜렉터는 100개의 에이전트당 하나씩 구동되며, 데이터 중복 제거 등의 작업은 맵리듀스로 처리합니다. 야후!에서 개발했으며, 아파치 오픈소스 프로젝트로 공개돼 있습니다.
- Flume(http://flume.apache.org)
플럼(Flume)은 척와처럼 분산된 서버에 에이전트가 설치되고, 에이전트로부터 데이터를 전달받는 콜랙터로 구성됩니다. 차이점은 전체 데이터의 흐름을 관리하는 마스터 서버가 있어서 데이터를 어디서 수집하고, 어떤 방식으로 전송하고, 어디에 저장할지를 동적으로 변경할 수 있습니다. 클라우데라에서 개발했으며, 아파치 오픈소스 프로젝트로 공개돼 있습니다.
- Scribe(https://github.com/facebook/scribe)
페이스북에서 개발한 데이터 수집 플랫폼이며, Chukwa와는 다르게 데이터를 중앙 집중 서버로 전송하는 방식입니다. 최종 데이터는 HDFS 외에 다양한 저장소를 활용할 수 있으며, 설치와 구성이 쉽게 다양한 프로그램 언어를 지원합니다. HDFS에 저장하려면 JNI(Java Native Interface)를 이용해야 합니다.
- Sqoop(http://sqoop.apache.org)
스쿱(Sqoop)은 대용량 데이터 전송 솔루션이며, 2012년 4월에 아파치의 최상위 프로젝트로 승격됐습니다. Sqoop은 HDFS, RDBMS, DW, NoSQL 등 다양한 저장소에 대용량 데이터를 신속하게 전송하는 방법을 제공합니다. 오라클, MS-SQL, DB2 등과 같은 상용 RDBMS와 MySQL, 포스트그레스큐엘(PostgreSQL)과 같은 오픈소스 RDBMS 등을 지원합니다.
- Hiho(https://github.com/sonalgoyal/hiho)
스쿱과 같은 대용량 데이터 전송 솔루션이며, 현재 깃헙(GitHub)에 공개돼 있습니다. 하둡에서 데이터를 가져오기 위한 SQL을 지정할 수 있으며, JDBC 인터페이스를 지원합니다. 현재는 오라클과 MySQL의 데이터 전송만 지원합니다.
- Kafka(http://kafka.apache.org) 카프카(Kafka)는 데이터 스트림을 실시간으로 관리하기 위한 분산 메세징 시스템입니다. 2011년 링크드인에서 자사의 대용량 이벤트처리를 위해 개발됐으며, 2012년 아파치 탑레벨 프로젝트가 됐습니다. 발행(publish)-구독(subscribe) 모델로 구성되어 있으며, 데이터 손실을 막기 위하여 디스크에 데이터를 저장합니다. 파티셔닝을 지원하기 때문에 다수의 카프카 서버에서 메세지를 분산 처리할 수 있으며, 시스템 안정성을 위하여 로드밸런싱과 내고장성(Fault Tolerant)를 보장합니다. 다수의 글로벌 기업들이 카프카를 사용하고 있으며, 그중 링크드인은 하루에 1조1천억건 이상의 메세지를 카프카에서 처리하고 있습니다.
데이터 처리
- Pig(http://pig.apache.org)
피그(Pig)는 야후에서 개발됐으나 현재는 아파치 프로젝트에 속한 프로젝트로서, 복잡한 맵리듀스 프로그래밍을 대체할 피그 라틴(Pig Latin)이라는 자체 언어를 제공합니다. 맵리듀스 API를 매우 단순화한 형태이고 SQL과 유사한 형태로 설계됐습니다. SQL과 유사하기만 할 뿐, 기존 SQL 지식을 활용하기가 어려운 편입니다.
- Mahout(http://mahout.apache.org)
머하웃(Mahout)은 하둡 기반으로 데이터 마이닝 알고리즘을 구현한 오픈소스 프로젝트입니다. 현재 분류(classification), 클러스터링(clustering), 추천 및 협업 필터링(Recommenders/collaborative filtering), 패턴 마이닝(Pattern Mining), 회귀 분석(Regression), 차원 리덕션(Dimension reduction), 진화 알고리즘(Evolutionary Algorithms) 등 중요 알고리즘을 지원합니다. Mahout을 그대로 사용할 수도 있지만 각 비즈니스 환경에 맞게 최적화해서 사용하는 경우가 많습니다.
- Spark(http://spark.apache.org)
스파크(Spark)는 인메모리 기반의 범용 데이터 처리 플랫폼입니다. 배치 처리, 머신러닝, SQL 질의 처리, 스트리밍 데이터 처리, 그래프 라이브러리 처리와 같은 다양한 작업을 수용할 수 있도록 설계되어 있습니다. 2009년 버클리 대학의 AMPLab에서 시작됐으며, 2013년 아파치 재단의 인큐베이션 프로젝트로 채택된 후, 2014년에 탑레벨 프로젝트로 승격됐습니다. 현재 가장 빠르게 성장하고 있는 오픈소스 프로젝트 중의 하나이며, 사용자와 공헌자가 급격하게 증가하고 있습니다.
- Impala(http://impala.io)
임팔라(Impala)는 클라우데라에서 개발한 하둡 기반의 분산 쿼리 엔진입니다. 맵리듀스를 사용하지 않고, C++로 개발한 인메모리 엔진을 사용해 빠른 성능을 보여줍니다. 임팔라는 데이터 조회를 위한 인터페이스로 HiveQL을 사용하며, 수초 내에 SQL 질의 결과를 확인할 수 있습니다. 2015년말 아파치 재단의 인큐베이션 프로젝트로 채택됐습니다.
- Presto(https://prestodb.io) 프레스토(Presto)는 페이스북이 개발한 대화형 질의를 처리하기 위한 분산 쿼리 엔진입니다. 메모리 기반으로 데이터를 처리하며, 다양한 데이터 저장소에 저장된 데이터를 SQL로 처리할 수 있습니다. 특정 질의 경우 하이브 대비 10배 정도 빠른 성능을 보여주며, 현재 오픈소스로 개발이 진행되고 있습니다.
- Hive(http://hive.apache.org)
하이브(Hive)는 하둡 기반의 데이터웨어하우징용 솔루션입니다. 페이스북에서 개발했으며, 오픈소스로 공개되며 주목받은 기술입니다. SQL과 매우 유사한 HiveQL이라는 쿼리 언어를 제공합니다. 그래서 자바를 모르는 데이터 분석가들도 쉽게 하둡 데이터를 분석할 수 있게 도와줍니다. HiveQL은 내부적으로 맵리듀스 잡으로 변환되어 실행됩니다.
- Tajo(http://tajo.apache.org)
타조(Tajo)는 고려대학교 박사 과정 학생들이 주도해서 개발한 하둡 기반의 데이터 웨어하우스 시스템입니다. 2013년 아파치 재단의 인큐베이션 프로젝트로 선정됐으며, 2014년 4월 최상위 프로젝트로 승격됐습니다. 맵리듀스 엔진이 아닌 자체 분산 처리 엔진을 사용하며, HiveQL을 사용하는 다른 시스템들과는 다르게 표준 SQL을 지원하는 것이 특징입니다. HDFS, AWS S3, H베이스, DBMS 등에 저장된 데이터 표준 SQL로 조회할 수 있고, 이기종 저장소간의 데이터 조인 처리도 가능합니다. 질의 유형에 따라서 하이브나 스파크보다 1.5 ~ 10배 빠른 성능을 보여줍니다.
워크플로우 관리
- Oozie(http://oozie.apache.org)
우지(Oozie)는 하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템입니다. 자바 서블릿 컨테이너에서 실행되는 자바 웹 애플리케이션 서버이며, 맵리듀스 작업이나 피그 작업 같은 특화된 액션으로 구성된 워크플로우를 제어합니다.
데이터 시각화
- Zeppelin (https://zeppelin.incubator.apache.org) 제플린(Zeppelin)은 빅데이터 분석가를 위한 웹 기반의 분석 도구이며, 분석결과를 즉시 표, 그래프로 제공하는 시각화까지 지원합니다. 아이파이썬(iPython)의 노트북(Notebook)과 유사한 노트북 기능을 제공하며, 분석가는 이를 통해 손쉽게 데이터를 추출, 정제, 분석, 공유를 할 수 있습니다. 또한 스파크, 하이브, 타조, 플링크(Flink), 엘라스틱 서치, 카산드라, DBMS 등 다양한 분석 플랫폼과 연동이 가능합니다. 2013년 엔에프랩의 내부 프로젝트로 시작됐으며, 2014년 아파치 재단의 인큐베이션 프로젝트로 선정됐습니다.
데이터 직렬화
- Avro(http://avro.apache.org)
RPC(Remote Procedure Call)와 데이터 직렬화를 지원하는 프레임워크입니다. JSON을 이용해 데이터 형식과 프로토콜을 정의하며, 작고 빠른 바이너리 포맷으로 데이터를 직렬화합니다. 경쟁 솔루션으로는 아파치 쓰리프트(Thrift), 구글 프로토콜 버퍼(Protocol Buffer) 등이 있습니다.
- Thrift(http://thrift.apache.org) 쓰리프트(Thrift)는 서로 다른 언어로 개발된 모듈들의 통합을 지원하는 RPC 프레임워크입니다. 예를 들어 서비스 모듈은 자바로 개발하고, 서버 모듈은 C++로 개발되었을때, 쓰리프트로 쉽게 두 모듈의 통신 코드를 생성할 수 있습니다. 쓰리프트는 개발자가 데이터 타입과 서비스 인터페이스를 선언하면, RPC 형태의 클라이언트와 서버 코드를 자동으로 생성합니다. 자바, C++, C#, Perl, PHP, 파이썬, 델파이, Erlang, Go, Node.js 등과 같이 다양한 언어를 지원합니다.
출처 : http://blrunner.com/99
IT News 2016. 1. 18. 12:44
출처 : MIT OpenCourseWare YouTube 교수 : Eric Grimson, John Guttag 제 01강 - 연산이란 - 데이터 타입, 연산자 및 변수 소개 제 02강 - 연산자와 피연산자 - 분기문, 조건문 그리고 반복문 제 03강 - 공통 코드 패턴, 반복 프로그램 제 04강 - 기능을 통한 분해 및 추상화, 재귀 소개 제 05강 - 부동 소수점, 계통적 명세화, 루트 찾기 제 06강 - 이분법, 뉴턴/랩슨, 그리고 리스트 소개 제 07강 - 리스트와 가변성, 딕셔너리, 의사코드, 그리고 효율성 소개 제 08강 - 복잡성 - 로그, 선형, 이차 방정식, 지수 연산 알고리즘 제 09강 - 이진 탐색, 버블 그리고 분류 선택 제 10강 - 분할 정복 방법, 합병 정렬, 예외 제 11강 - 테스트와 디버깅 제 12강 - 디버깅 추가 강의, 배낭 문제, 동적 프로그래밍 소개 제 13강 - 동적 프로그래밍 - Overlapping subproblems, Optimal substructure 제 14강 - 배낭 문제 분석, 객체 지향 프로그래밍 소개 제 15강 - 추상 데이터 타입, 클래스와 메소드 제 16강 - 캡슐화, 상속, 쉐도잉 제 17강 - 연산 모델 - 랜덤워크 시뮬레이션 제 18강 - 시물레이션 결과 제시, Pylab, Plotting 제 19강 - 편향된 랜덤워크, 배포 제 20강 - 몬테카를로(Monte Carlo) 시뮬레이션, 추정 파이 제 21강 - 시뮬레이션 결과 검증, 곡선 적합, 선형 회귀 제 22강 - 일반, 균등 그리고 지수 분포 - 통계의 오류 제 23강 - 주식 시장 시뮬레이션 제 24강 - 과정 개요 - 컴퓨터 과학자들은 무엇을 하나요?
IT News 2015. 11. 10. 16:55
구글에서 Deep learning Library를 Open Source화 하였군요.
자세한 내용은 첨부된 내용들을 보면 될 것 같아요.
Python과 C++ 으로 Library 사용 가능~
소프트웨어 라이센스는 apache 2.0 입니다. 공개된 소스 코드를 이용해서 상업적인 프로그램을 개발하여 재패포 가능!!
TensorFlow Mechanics 101
The goal of this tutorial is to show how to use TensorFlow to train and evaluate a simple feed-forward neural network for handwritten digit classification using the (classic) MNIST data set. The intended audience for this tutorial is experienced machine learning users interested in using TensorFlow.
These tutorials are not intended for teaching Machine Learning in general.
Please ensure you have followed the instructions to Install TensorFlow.
Tutorial Files
This tutorial references the following files:
| File |
Purpose |
mnist.py |
The code to build a fully-connected MNIST model. |
fully_connected_feed.py |
The main code, to train the built MNIST model against the downloaded dataset using a feed dictionary. |
Simply run the fully_connected_feed.py file directly to start training:
python fully_connected_feed.py
Prepare the Data
MNIST is a classic problem in machine learning. The problem is to look at greyscale 28x28 pixel images of handwritten digits and determine which digit the image represents, for all the digits from zero to nine.

Download
At the top of the run_training() method, the input_data.read_data_sets() function will ensure that the correct data has been downloaded to your local training folder and then unpack that data to return a dictionary of DataSet instances.data_sets = input_data.read_data_sets(FLAGS.train_dir, FLAGS.fake_data)
NOTE: The fake_data flag is used for unit-testing purposes and may be safely ignored by the reader.
| Dataset |
Purpose |
data_sets.train |
55000 images and labels, for primary training. |
data_sets.validation |
5000 images and labels, for iterative validation of training accuracy. |
data_sets.test |
10000 images and labels, for final testing of trained accuracy. |
For more information about the data, please read the Download tutorial.
Inputs and Placeholders
The placeholder_inputs() function creates two tf.placeholder ops that define the shape of the inputs, including the batch_size, to the rest of the graph and into which the actual training examples will be fed.images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,
IMAGE_PIXELS))
labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size))
Further down, in the training loop, the full image and label datasets are sliced to fit the batch_sizefor each step, matched with these placeholder ops, and then passed into the sess.run() function using the feed_dict parameter.
Build the Graph
After creating placeholders for the data, the graph is built from the mnist.py file according to a 3-stage pattern: inference(), loss(), and training().
inference() - Builds the graph as far as is required for running the network forward to make predictions.loss() - Adds to the inference graph the ops required to generate loss.training() - Adds to the loss graph the ops required to compute and apply gradients.
Detail Contents -->  Getting Started - TensorFlow.pdf Getting Started - TensorFlow.pdf
Reference URL : http://tensorflow.org/
IT News 2015. 11. 9. 16:52
[컴퓨터월드] 세상은 점점 더 빨라지고, 복잡해지고 있다. IT기술의 발전에 따라 데이터는 폭증하며 급류를 이루기 시작했고, 만물이 이어지는 초연결사회(Hyper-Connected Society)의 도래가 임박했다. 이러한 변화로 인해 경쟁마저 더욱 빠르고 복잡하게 전개되는 양상을 보인다. 치열해지는 경쟁에서 생존하기 위해서는 보다 빠르고 명확한 의사결정이 필수적이다. 이에 빅데이터 속에서 실질적인 인사이트를 실시간으로 얻는 것이 화두가 되고 있다.
최근 관련업계에서는 사물인터넷(IoT) 시대를 맞아 각종 기계로부터 쏟아지고 있는(machine-generated) 데이터에 대한 관심이 점차 늘어나고 있다. 사람들이 만들어내는(human-generated) 데이터와 달리, 기계는 끊임없이 정보를 쏟아내면서도 그 속에 거짓말은 찾을 수 없다. 이곳을 출발지로 삼으면서 실시간 빅데이터 분석 시장이 태동하고 있는 것이다. 각자 고유의 무기를 내세워 이 새로운 전장에 출사표를 던진 이들의 행보를 간단히 살펴본다.
IoT 시대, 분석거리가 쏟아진다
‘IoT’와 ‘분석’은 현재 가장 각광받고 있는 IT트렌드에 속한다. 시장조사기관 가트너는 지난해 말 ‘2015년 10대 전략 기술 동향’을 발표, 향후 3년간 기업에 주요한 영향을 미칠 가능성이 있는 기술들 가운데 이 두 가지를 선정했다. IoT 시대를 맞아 디지털화로 인해 생성되는 데이터 흐름과 서비스의 융합은 관리(manage), 현금화(monetize), 운영(operate), 확장(extend)이라는 네 가지 IoT 사용 모델을 창조, 모든 기업들은 산업과 무관하게 이 기본 모델을 활용해 디지털 비즈니스를 영위할 수 있게 됐다.
아울러 임베디드(embedded) 시스템이 생성하는 데이터의 양이 증가하고 기업 내외 정형·비정형 데이터 풀(pool) 분석이 가능해지면서 분석이 보편화되고 있다. 기업들은 IoT, 소셜 미디어, 웨어러블 기기에서 생성된 대량의 데이터를 적절히 분류, 알맞은 정보를 제때 필요한 곳에 정확히 전달하는 것을 과제로 안게 됐다. 이에 가트너는 분석 기술이 모든 곳에 내장돼 끝단에서 데이터가 처리되는 ‘엣지 애널리틱스(Edge Analytics)’가 대두될 것으로 보고 있다.
이러한 변화는 점차 가속화되고 있다. 시장조사기관 IDC는 오는 2018년까지 IoT에서 생성된 데이터의 40%가 보관되고 프로세스를 거쳐 분석될 것으로 예상했다. 또한 현재는 IoT의 50% 이상이 제조, 운송, 스마트시티 및 컨슈머 애플리케이션 분야에 집중돼있지만, 향후 5년 내 전 산업에서 IoT가 활성화될 전망이다. IDC는 기업들이 네트워크에 연결된 수많은 디바이스로부터 쇄도하는 데이터를 효과적으로 조율하기 위한 방안을 고심해봐야 한다고 강조했다.
IDC에 따르면, 글로벌 IoT 시장은 지난해 6,558억 달러에서 연평균 16.9% 성장, 오는 2020년에는 1조 7천억 달러 규모를 형성할 것으로 전망된다. 특히 한국을 비롯한 아시아·태평양지역(일본 제외)의 IoT 산업도 높은 성장세를 지속, 연결된 기기 및 사물(things) 대수가 31억 대에서 86억 대 규모로 증가할 것으로 내다봤다. 동기간 이 지역의 IoT 시장은 2,500억 달러에서 5,830억 달러 규모로 성장할 것으로 바라보고 있다.
기업이 관리하는 데이터 중 비정형데이터가 정형데이터보다 더 많아지고 있고, 빅데이터가 IoT와 결합하면서 웨어러블 시장 및 맞춤형 추천, 유통과 교통에 이르기까지 폭넓은 분야에 새로운 기술이 적용될 것으로 보인다. 지능적 보안 및 안보 분야에서도 실시간 모니터링과 리스크 감지 시장이 급격히 성장하고 있다. 특히 제조업 중심의 한국은 스마트팩토리 등 인더스트리 4.0 구현의 중요한 시장이 될 것이다.
실시간 분석 수요 확대
IoT 시대의 도래에 따라 빅데이터의 ‘실시간 분석’에 대한 니즈가 급증하고 있다. ‘온라인 분석’은 데이터의 생성 시점과 분석 시점의 구분이 없는 반면, ‘실시간 분석’은 데이터가 생성되는 시점에 최대한 가깝게 분석이 함께 이뤄진다. 이 ‘실시간’에 대한 기준은 업무 성격에 따라 분 단위, 초 단위, 1초 미만 등으로 다양하게 정의되고 있으나, 갈수록 이에 대한 요건이 다양화되는 동시에 강화되고 있는 추세다.
IoT 시대의 실시간 분석은 수많은 센서나 소셜미디어에서 생성되는 시계열(time series) 데이터를 그 대상으로 하며, 특히 각종 기계로부터 생성되는 로그데이터가 주재료가 되고 있다. 머신데이터는 빅데이터 중에서도 증가세가 가장 빠른 영역이며, 다양한 트랜잭션과 고객 행동, 센서 기록, 기계 설비 거동, 보안 위협, 사기 행위 등을 파악할 수 있다는 점에서 보다 빠르고 정확하게 실질적인 가치를 얻을 수 있다는 특징을 지녔다.
실시간 분석 솔루션을 표방하는 소프트웨어(SW) 기술들은 기존 OLAP(온라인분석처리) 영역의 분석용 데이터베이스관리시스템(DBMS)나 데이터웨어하우스(DW)와도 다소 차이를 보인다. 마치 라면을 조리할 시간과 여건이 부족할 때는 간단히 취식할 수 있는 컵라면을 찾는 것과 같다. 데이터를 분석하기 위해 ETL(추출·변환·적재)을 비롯한 여러 과정을 거쳐 DW에서 주기적으로 배치(batch) 처리할 필요 없이, 생성되는 데이터를 바로 처리하고 분석해 필요한 만큼의 인사이트를 빠르게 얻을 수 있는 것이다.
이러한 민첩성(agility)은 하둡(Hadoop)을 위시한 오픈소스 빅데이터 플랫폼과의 가장 큰 차이점이다. 하둡은 배치성 아키텍처를 근간으로 하므로 실시간성과는 동떨어져 있어, 인메모리(in-memory) 기술이 적용된 ‘아파치 스파크(Apache Spark)’ 등을 통해 이에 대한 보완도 진행되고 있다. 그러나 기업이 하둡에코시스템을 제대로 활용하기 위해 요구되는 대규모 컴퓨팅파워와 이를 유지관리하기 위해 필요한 고급인력은 결국 TCO(총소유비용)의 증가를 야기한다는 점에서 여전히 생각해볼 문제로 남는다. 더불어 실시간 분석 솔루션들은 짧은 구축기간, SQL 활용 등 사용성을 무기로 삼아 이 틈새를 공략하고 있다.
스트리밍 데이터를 메모리상에서 바로 연관분석을 수행하는 CEP(복합이벤트처리) 기술은 실시간 분석 솔루션과 상호보완적인 관계로 볼 수 있다. CEP 기술은 데이터의 저장 단계 전에 특정 로직을 통해 예외상황 등의 이벤트를 확인하고 처리하는 방식이므로, 저장된 데이터를 가공하거나 검색하는 기능이 없고 입력되는 데이터를 다루는 범위도 한계를 지니게 된다. 그러나 CEP 기술은 빠른 응답속도에 강점을 갖고 있어, 실시간 분석 솔루션의 앞단에 위치하거나 또는 내장돼 공존하며 시너지를 내는 것이 가능하다.
같은 목적, 다른 접근
실시간 분석 솔루션은 빠르게 성장하는 새로운 시장으로, 장차 우리에게 어떤 영향을 미치게 될 것인지 아직 가늠하기 어려운 부분도 있다. 그러나 현재까지의 활용사례는 빙산의 일각에 불과하다는 것이 업계의 중론이다. IT벤더들은 ‘빅데이터’와 ‘실시간’이라는 두 축을 모두 지원하기 위해 다양한 형태의 솔루션을 선보이며 시장을 공략하고 있다.
이러한 실시간 분석 솔루션은 공통적으로 빠른 색인(indexing)을 지원하며, 크게 컬럼형DBMS에서 파생된 유형과 로그처리시스템에서 발전된 유형으로 구분할 수 있다. 컬럼형DBMS에서 파생된 유형의 경우 DML(데이터조작언어) 가운데 수정(update)과 삭제(delete)를 지원하지 않는 대신 입력(insert)과 검색(select)을 위한 성능을 극대화시키는 등의 방식을 취한다. 로그처리시스템에서 발전된 유형의 경우 NoSQL DB처럼 스키마(schema)를 고정하지 않고 로(raw)데이터 자체를 실시간 인덱싱하고 향후 분석 대상을 재정의하는 스키마리스(schema-less) 형태로 저장한다.
이 같은 일률적인 기준으로 구분하기에는 적절치 못할 수 있으나, 컬럼형DBMS에서 파생된 솔루션으로는 ▲파스트림 ▲아이리스DB ▲인피니플럭스 등을 들 수 있고, 로그처리시스템에서 발전된 솔루션으로는 ▲스플렁크 ▲테라스트림 바스 ▲로그프레소 ▲D2 등을 꼽을 수 있다. IoT 시대의 실시간 빅데이터 분석 니즈를 고유의 방식으로 풀어가고 있는 이 솔루션들과 각사의 전략에 대해 알아본다.
경쟁사들도 인정한 스피드 DBMS ‘파스트림’
굿모닝아이텍이 국내 총판을 맡고 있는 ‘파스트림(ParStream)’은 병렬처리의 ‘Parallel’과 스트리밍 데이터의 ‘Streaming’을 조합해 만들어진 이름이다. 파스트림사는 지난 2008년 독일에서 설립돼 현재는 실리콘밸리에 본사를 두고 있으며, 대부분의 기술진들이 C++에 대한 세계 최고 수준의 기술력을 가진 R&D 전문 인력이다.
‘파스트림’의 시초는 창업자들이 이전에 진행했던 여행 패키지 관리 프로젝트였다. 독일은 여행사가 판매한 여행 패키지 서비스에 대해 모든 것을 책임지는 구조로, 기상 조건에 의해 결항된다거나 예기치 못한 상황이 일어나는 것을 실시간으로 조정하고 관리할 필요가 있었다. 수십억 건의 데이터를 대상으로 모든 서비스에 응답속도 3초 이내가 요구사항이었으나, 이를 충족하는 솔루션을 찾지 못했다. 그래서 이를 위해 독자적으로 새로운 시도를 꾀한 끝에 탄생한 결과물이 바로 ‘파스트림’이다.
| |
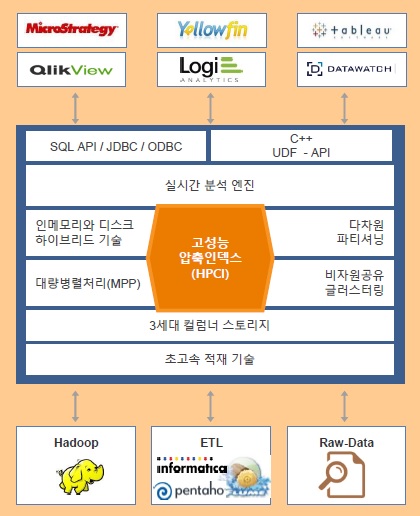 |
|
| ▲ ‘파스트림’ 구조 및 생태계 |
‘파스트림’ 분석플랫폼은 IoT와 빅데이터 환경의 대량 데이터를 초고속으로 처리할 수 있도록 개발된 컬럼형 DBMS로, 기존 DBMS나 DW시스템과는 추구하는 목적이 다르다. 기본적으로 OLTP(온라인트랜잭션처리)를 목적으로 하지 않기 때문에, 데이터의 업데이트와 딜리트 등을 지원하지 않고 빠르게 대량 인서트 및 스트리밍 데이터를 처리하면서 동시에 질의(쿼리)가 가능하도록 설계됐다. 실시간 분석을 지원하기 위해, 기존 DBMS에서 정합성을 보장하기 위한 고유 기술 중 하나인 록킹(locking) 메카니즘을 과감하게 제거한 제품이다.
MPP(대용량병렬처리) 및 인메모리 기술 등 기존의 검증된 기술을 채용해 대량의 데이터를 빠르게 처리할 수 있고, 나아가 HPCI(고성능압축인덱스)와 GDA(지역분산분석) 등의 고유 기술을 특징으로 삼고 있다. 대개의 경우 압축된 데이터를 메모리상에서 처리하기 위해서는 다시 압축을 풀어야 하지만, HPCI 기술은 압축을 풀지 않고도 가능하므로 기존 분석용 DBMS 대비 수십 배 빠르면서 더 적은 용량을 필요로 한다. 또 GDA 기술은 데이터를 중앙에 모아 처리할 필요 없이 지역별로 데이터 소스 가까이에서 실시간 분석과 저장을 지원, 가트너의 ‘엣지 애널리틱스’나 시스코의 ‘포그 컴퓨팅(Fog Computing)’을 구현할 수 있도록 돕는다.
‘파스트림’은 기하급수적으로 증가하는 IoT 빅데이터 처리 및 분석을 목적으로 순수하게 C++로 개발된 솔루션으로, 하둡 기술을 이용하지는 않았지만 분산처리 및 확장성에서는 일부 하둡 사상을 채용했다. 일반적인 RDBMS(관계형DBMS) 구조를 가지면서 표준 SQL을 지원하며, AWS(아마존웹서비스)를 비롯한 클라우드 환경에서도 ‘파스트림’을 사용할 수 있다. 다양한 기업들과 IoT를 위한 협업 생태계를 구축해 BI(비즈니스인텔리전스)나 ETL 등의 분야에서 기존 검증된 대부분의 솔루션을 연계 및 활용할 수 있는 것도 강점으로, 굿모닝아이텍과 함께 국내에서도 IoT 생태계 구축에 나서고 있다.
| [인터뷰] “혁신적인 기술로 차별화된 실시간 빅데이터 분석DB”
| |
 |
|
| ▲ 조외현 파스트림코리아 대표 |
파스트림, 어디에 쓰이나.
‘파스트림’은 필요 없는 기능들을 배제하고 실시간 IoT 빅데이터 분석에 특화된 DBMS라 가볍고 빠르다. 자동차로 비유한다면 세단이나 SUV가 아니라, 레이싱을 위한 스포츠카라고 할 수 있다. 기존 DBMS와는 달리 실시간으로 데이터를 분석해 인사이트를 얻을 수 있도록 최적화됐으며, 구조적인 한계를 지닌 로그관리시스템 등과는 달리 실제 대규모 데이터를 다양한 기법으로 처리할 수 있도록 지원한다. 무엇보다 간단하게 빅데이터 분석을 시작해볼 수 있다는 점이 매력이다.
초기에는 유통, 이커머스, 과학 분야 등에서 기존 업무를 대상으로 빅데이터를 빠르게 분석하기 위해 적용됐다. 최근에는 IoT 분야 적용사례가 급속히 늘고 있다. 대표적으로 중국 인비전에너지는 운영 중인 풍력발전기 2만대에 대한 실시간 분석 모니터링에 ‘파스트림’을 적용, 연간 1,700억 원에 달하는 효과를 거두고 있다. 또 옥토텔리매틱스는 운전자의 운전습관을 자동차보험과 접목해 사고예방은 물론 비용절감 효과를 거두고 있으며, 지멘스는 터빈당 5,000개의 센서를 통해 데이터를 수집·분석해 더욱 효율적인 가스터빈을 만드는데 활용하고 있다.
파스트림의 향후 계획은.
‘파스트림’은 신재생에너지 분야를 주도하는 유럽을 중심으로 활성화되고 있는 IoT 분야 적용사례를 확보하면서 분석플랫폼으로 자리매김하고 있고, 강점을 살릴 수 있는 IoT 시장과 실시간성 요건의 확대에 따라 앞으로의 전망도 밝다고 본다. 또한 IoT 분야는 너무 다양하기 때문에, 전문성 있는 기존 솔루션을 포용하는 협업생태계 전략을 취하면서 고객에게 확실한 신뢰와 장기적 비전을 제시하고 있다.
한편, 전 세계 빅데이터 시장규모를 보면 지난해 기준으로 순수 하둡이 전체 시장의 1% 미만으로 조사됐다. 전문가들은 2~3년 후도 이와 크게 다르지 않을 것이며, 컨설팅과 전문서비스 매출을 합해도 3% 정도가 될 것이라고 예측한다. 하둡이 빅데이터 시장 창출에 기여한 것은 사실이지만 활성화에는 한계를 보이고 있는 것으로, 이를 보완하기 위해 다양한 기술들이 개발되고 있으나 이들의 미래 또한 검증되지 않은 상황이다. 현재 빅데이터 분야는 춘추전국시대로, 이제는 국내에서도 맹목적인 글로벌 기술 추종과 시행착오에서 벗어나 보다 현실적인 대안을 검토할 필요가 있다고 본다. |
모비젠의 IoT 빅데이터 DB 어플라이언스 ‘아이리스DB’
지난 2000년 설립된 모비젠은 창사 이래로 대규모 통신망 및 네트워크 관리, 대용량 데이터 및 트래픽 처리에 기술을 쌓아온 기술 주도형 벤처다. 장기간 누적된 대용량 데이터 처리 및 분석 능력을 기반으로 빅데이터 처리 솔루션 및 망수준의 관리운용 솔루션(품질관리, 장애관리, 보안관리)을 공급하고 있다.
회사의 주요 고객 가운데 이동통신사가 포함되는 모비젠은 통신망의 발전에 따라 빠르게 증가하는 데이터 트래픽을 분석하기 위해 필연적으로 대용량 빅데이터 시스템을 구축, 실제적인 통신망의 요구에 부응하기 위해 빅데이터 분석 솔루션을 개발하게 됐다. 경쟁이 치열한 이동통신사들의 데이터 분석 요구는 항상 시장을 선도하는 것으로, 이에 대응하는 솔루션을 만드는 것이 필요했다. 이에 따라 PB(페타바이트) 수준의 대규모 데이터를 준실시간으로 모니터링하기 위한 데이터 분석 플랫폼 ‘아이리스DB(IRIS DB)’를 선보였다.
어플라이언스 형태로 공급되는 ‘아이리스DB’는 겉보기에는 기존 OLAP 영역의 DBMS 제품들과 별반 다르지 않지만, 급속도로 발전하는 이동통신환경에서의 통신데이터 처리에 초점을 맞춰 개발돼 일일 100 TB(테라바이트)에 이르는 데이터를 분 단위로 처리 및 분석 가능한 것이 강점이다. 주로 네트워크 모니터링에 사용되며, 보안관제에 쓰이기도 한다.
| |
  |
|
| ▲ 모비젠 ‘아이리스DB’ 구조 |
‘아이리스DB’는 메모리와 디스크를 모두 활용하는 하이브리드 방식으로, 메모리를 마치 파일시스템처럼 쓸 수 있게끔 구현됐다. 메모리에 데이터를 우선적으로 저장하면서 시간이 지나면 디스크로 보내는 구조로, 100% 메모리상에서 처리된다. 특히 인서트 성능을 극대화하기 위해 PB 규모의 데이터도 1 GB(기가바이트) 단위로 나눠 저장되는 점이 특징이다. 이를 통해 실시간 색인을 지원, IT운영에 필수적인 장애 대응과 품질 관리에 적합하도록 설계됐다.
‘아이리스DB’는 분산 환경에서의 데이터 처리를 위한 SQL을 대부분 지원해 추가적인 교육을 필요로 하지 않고, 단기간에 비용효율적으로 구축 가능하다. 최근에는 ‘아파치 스파크’를 통합, 하둡을 사용하고 있는 기존 고객들에게 편의를 더했다. 실시간 SQL 성능과 함께 장기간의 SQL 및 배치성·대화형 SQL 성능까지 향상시켰고, 대규모 빅테이블에 대한 조인(JOIN) 연산을 포함한 모든 SQL 분석 작업이 가능해져 기존 단일 DBMS 기반 레거시(legacy) 시스템을 대규모 분산 병렬화하는 작업에도 활용할 수 있게 됐다.
향후 모비젠은 세계적으로 앞서있는 국내 통신망 환경에서의 경험을 바탕으로 글로벌 시장 공략에 박차를 가할 계획이며, 주요 타깃은 중국과 일본 등 아시아 시장이다. 아울러 고급분석(Advanced Analytics)에 대한 고객들의 니즈에 부응, 그간 SI(시스템통합) 성격으로 진행해오던 기계학습(머신러닝) 관련 요소를 더욱 발전시켜 솔루션 형태로 상용화하는 것을 목표로 하고 있다.
| [인터뷰] “실시간성, 비용효율성, 사용편의성 고루 갖춰”
| |
 |
|
| ▲ 김형근 모비젠 연구소장 |
아이리스DB, 어디에 쓰이나.
모비젠은 머신데이터 분야에 초점을 맞추고 있으며, 높은 QoS(서비스품질)를 요구하는 곳의 실시간 데이터 관리에 최적화돼있다. 특히 높은 실시간성, 확실한 확장성, 풀 텍스트 검색, SQL 지원 등 국내 기업 환경에서 필요로 하는 핵심 요소들을 골고루 제공하고 비용효율적으로 구축할 수 있다는 것이 특장점이다. 대규모 머신데이터가 들어오는 곳 어디든 배치해 DB로 쓸 수 있고, 스토리지로도 쓸 수 있다.
‘아이리스DB’는 주로 통신망 관리, 보안관제 등에 사용된다. LTE망 품질관리, 대규모 보험사의 IT시스템 데이터 유출 모니터링 시스템 구축에 활용된다. 모든 패킷을 검사해 데이터 과금을 관리하는 이동통신사에서 ‘아이리스DB’를 활용, 기존 ‘오라클 엑사데이타’의 부하를 현저히 줄여준 사례도 있다. 향후 대량의 머신데이터가 빠르게 늘어날 것이라 예측되므로, ‘아이리스DB’와 같은 실시간 머신데이터 분석용 플랫폼을 찾는 수요는 더 많아질 것이다.
모비젠의 향후 계획은.
하둡으로 촉발된 빅데이터 기술이 아직 시장에서 완전히 안정화되지 않았다. 빅데이터 도입은 곧 하둡 도입으로 당연시했던 상황에서, 점차 고객들이 그 복잡도, 성능저하, 용량의 압박 등을 경험하고 있다. 고객사 중 국내 모 게임사의 경우 하둡에서 분산 빅데이터DB 도입으로 방향을 전환하려 하고 있다. 본격적인 빅데이터 분석 플랫폼 도입은 아직 시작되지 않았다고 볼 수 있다. 앞으로 하둡의 한계가 시장에 알려지면, 자연스럽게 솔루션형 빅데이터DB 시장이 열릴 것으로 기대하고 있다.
시간은 우리 편이라고 생각한다. 데이터의 증가와 실시간 분석의 요구는 필연적으로 빅데이터DB의 도입으로 귀결될 것으로 보인다. 주로 기존에 DW를 구축했던 곳의 DW 업그레이드 과제를 주 타깃으로 삼고 있다. DW의 용량확장, 백업·아카이빙 시 급증하는 비용을 ‘아이리스DB’가 효과적으로 해결해줄 수 있기 때문이다. 대규모 IT시스템 구축과제에서는 DBMS를 필수적인 부품처럼 도입하듯, 앞으로는 빅데이터DB도 거의 모든 프로젝트에서 도입하게 될 것이다. ‘아이리스DB’의 시장은 빠르게 넓어질 것으로 기대하고 있다. |
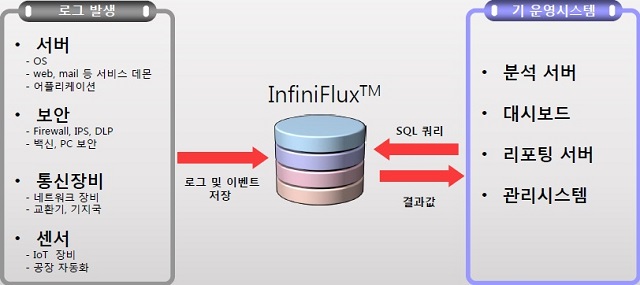
새롭게 등장한 시계열 빅데이터 DBMS ‘인피니플럭스’
김성진 전 알티베이스 대표가 지난 2013년 설립한 인피니플럭스(InfiniFlux)는 빅데이터 가운데 센서나 머신으로부터 발생하는 시계열 데이터를 실시간으로 저장하고 처리할 수 있는 DBMS를 전문적으로 개발하는 벤처기업이다. 기존 DBMS에서 처리하지 못하던 대량의 실시간 데이터를 새로운 아키텍처를 기반으로 분석할 수 있는 솔루션을 개발하는데 초점을 맞추고 있다.
전통적인 DBMS들은 트랜잭션 처리를 위해 ACID(원자성·일관성·고립성·지속성)를 만족해야 하는 제약사항이 있어 안정적이고 일관성 있는 데이터 처리에 주안점을 뒀으나, 최근 들어 폭증하는 수많은 센서 및 머신 데이터를 적절하게 처리하고자 하는 요구가 많아지고 있다. 이에 인피니플럭스는 전통적인 DB기술과 실시간 빅데이터 처리 기술을 결합, 기존 DB처럼 조작하면서도 실시간 시계열 데이터 처리에 특화된 새로운 솔루션을 개발해 선보였다.
| |
 |
|
| ▲ ‘인피니플럭스’ 개요 |
기업명과 동명인 ‘인피니플럭스’는 정형·반정형데이터를 실시간으로 처리하기 위한 컬럼 기반 DBMS로, 데이터 발생량이 클수록 데이터의 발생시점과 실제 저장되고 다시 검색되는 시점의 시간적인 간격이 벌어지게 되는 기존 솔루션들과 달리 이러한 간격이 최소화되도록 설계된 점이 특징이다. 이를 위해 실시간 인덱스 구성, 실시간 질의처리, 실시간 데이터 압축, 병렬 디스크 활용 등의 기술을 자체 개발해 적용했다. DBMS로서의 트랜잭션 처리는 배제, DML 가운데 업데이트를 지원하지 않으나 인서트와 셀렉트를 위한 성능이 강화됐다.
이를 통해 싱글노드에서의 데이터 저장 및 분석 속도를 극대화하면서 효율성까지 갖춰, 초당 10만 건 이상의 데이터를 저장하고 검색할 수 있을 뿐만 아니라 4TB 수준 디스크의 경우 100억 건 이상의 데이터를 저장하고 분석할 수 있는 성능을 지녔다. 특히 임베디드 환경에서 데이터를 빠르게 처리하는데 특장점을 지녔으며, 사용성도 중시해 누구나 웹사이트에서 다운로드 받아 테스트해볼 수 있게끔 패키지화가 진행됐다.
‘인피니플럭스’는 최근 시큐아이의 차세대 방화벽 MF2 시리즈에 도입됐으며, 모든 네트워크 패킷 정보의 저장·감시·관리를 위해 ETRI(한국전자통신연구원)에서 개발하고 있는 ‘사이버 블랙박스’ 프로젝트에도 채택됐다. 내년에는 MPP를 지원하는 차기 버전도 선보일 예정이다.
| [인터뷰] “시계열 빅데이터 DBMS로 글로벌 시장 정조준”
| |
 |
|
| ▲ 김성진 인피니플럭스 대표 |
인피니플럭스, 어디에 쓰이나.
비(非) 트랜잭션 형태 데이터가 트랜잭션 기반 데이터의 양을 넘은 상황에서, 고객들은 전통적 데이터 관리보다는 폭증하는 데이터의 저장과 관리에 더 관심을 보이고 있다. 앞으로는 시계열 빅데이터를 생산하는 IoT 혹은 관련 산업 영역에서 비즈니스 기회가 급증할 것으로 보며, 이러한 영역에서 준비된 시계열 전문 DBMS로 자리 잡고자 한다.
‘인피니플럭스’는 데이터의 실시간 응답성이 매우 높고, 그러한 데이터를 반드시 저장해야만 하는 요구가 있는 영역에서 잘 활용될 수 있다. 보안 장비에 탑재돼 초당 수만 건 이상 발생하는 시계열 데이터를 저장하는 곳에 쓰이고 있으며, 임베디드 환경에서 데이터를 초고속 처리할 수 있으므로 자동차, 선박, 비행기, 공장 자동화를 비롯해 병원 등 생체 센서 데이터 등 미션 크리티컬한 부분에서도 두각을 나타낼 것이다.
인피니플럭스의 향후 계획은.
다양한 형태의 실시간 시계열 빅데이터가 많이 발생할 수밖에 없는 메가트렌드에 우리가 서있다고 생각하며, 이 분야에서 세계 최고의 성능을 지닌 솔루션이라면 글로벌 시장에서도 좋은 성과가 있을 것으로 믿는다. 이런 관점에서 자사는 품질을 기반으로 패키지화를 진행하고, 모든 관련 문서와 자료를 영문화하며, 인지도 상승과 사용자 확보를 위한 오픈소스 전략도 고려하는 등 철저하게 글로벌 제품화를 꾀하고 있다. |
실시간 운영 인텔리전스 SW 대표주자 ‘스플렁크’
스플렁크(Splunk)는 실시간 운영 인텔리전스(Operational Intelligence) SW를 개발·공급하는 미국 기업으로, 로그데이터 검색엔진에서 발전해 현재는 실시간 분석 솔루션 시장을 선점하고 있다. 지난 6월 기준으로 포춘지 선정 100대 기업 중 80개를 포함해 글로벌 기업과 정부기관 9,500여 곳을 고객사로 확보하고 있으며, 스플렁크를 통해 매일 400TB가 넘는 데이터를 분석하는 고객도 존재한다. 최근에는 가트너 매직쿼드런트 SIEM(보안정보이벤트관리) 부문에서 3년 연속 리더로 선정된 바 있다.
스플렁크는 세 가지 키워드로 설명할 수 있다. 첫 번째는 엔터프라이즈다. 품질이나 확장성 및 다양한 유스케이스(use case)를 지원한다는 점에서 엔터프라이즈급 플랫폼을 제공한다. 두 번째는 솔루션이다. 전문가들과 외부 개발자 및 파트너들은 고객의 구체적인 유스케이스에 맞는 앱과 애드온(add-on)을 제공, 현재 ‘스플렁크베이스(Splunkbase)’에는 700여 건이 넘는 앱이 올라와 있다. 세 번째는 클라우드다. 모든 솔루션을 하나의 서비스로 제공할 수 있도록 설계해 개발기간을 단축하는 한편, 클라우드 솔루션과 온프레미스(on-premises) 솔루션 및 하이브리드 솔루션도 제공하고 있다.
| |
 |
|
| ▲ ‘스플렁크’ 기술 포트폴리오 |
핵심 플랫폼인 ‘스플렁크 엔터프라이즈’는 웹사이트, 비즈니스 애플리케이션, 소셜미디어 플랫폼, 앱 서버, 하이퍼바이저, 센서, 전통적인 DB, 오픈소스 데이터 저장소 등에서 준실시간으로 데이터를 수집·검색해 분석하고 시각화할 수 있다. ‘서치(search)’라는 고유의 명령 언어를 가졌고, 재인덱싱할 필요 없는 분산 구조로 데이터를 시계열 형태로 저장해 빠른 검색과 높은 확장성을 지원한다. 플랫폼으로서 앱 생태계가 잘 갖춰져 있어 전문적인 용도로도 다양하게 활용할 수 있고, 패키지화가 잘 이뤄져 웹사이트에서 다운로드받아 간편하게 테스트해볼 수도 있다.
이와 함께 스플렁크는 ‘스플렁크 엔터프라이즈’ 플랫폼을 기반으로 다양한 제품들을 제공하고 있다. 하둡용 분석 솔루션 ‘헝크(Hunk)’, 개인 사용자나 소규모 IT환경 대상 ‘스플렁크 라이트’, 클라우드 및 하이브리드 환경을 위한 ‘스플렁크 클라우드’, 모바일 앱의 성능과 문제 및 사용량을 파악할 수 있는 ‘스플렁크 민트(MINT)’ 등이다.
| [인터뷰] “간편하게 빅데이터 분석을 시도해볼 수 있는 플랫폼”
| |
 |
|
| ▲ 김대원 스플렁크코리아 지사장 |
스플렁크, 어디에 쓰이나.
스플렁크는 모든 산업군에 운영 인텔리전스 솔루션을 제공하고 있다. 실시간 분석 솔루션 시장은 스플렁크가 선도적으로 개척한 시장이라 자부한다. 스플렁크의 솔루션은 주로 보안과 IT운영관제 목적으로 쓰이며, 주요 고객은 정부, 온라인 서비스, 고등 교육기관, 금융, 의료, 리테일, IT, 게임 등 다양하다. 장기적으로는 제조 분야에 관심을 갖고 있다. 글로벌에서는 50%의 성장세를 유지하고 있으며, 국내도 이와 비슷한 수준이다.
스플렁크의 향후 계획은.
스플렁크의 목표는 장차 데이터 플랫폼의 표준으로 자리 잡는 것이다. 또한 플랫폼으로서 지속적으로 발전해나가는 생태계를 만들어나가는 것도 주요 목표다. 이는 스플렁크코리아의 목표이기도 하다. IT기술 트렌드를 선도하고 있는 입장에서 고객들과 파트너들에게 이점을 제공할 수 있다고 생각하며, 구호나 말뿐이 아니라 직접 활용해보고 결정할 수 있게끔 하고 있다. 이를 통해 고객의 불편이 해소되고 ROI(투자수익율)를 얻게 될 수 있다면 간편하게 빅데이터 분석을 시작할 수 있도록 지원하고자 한다. |
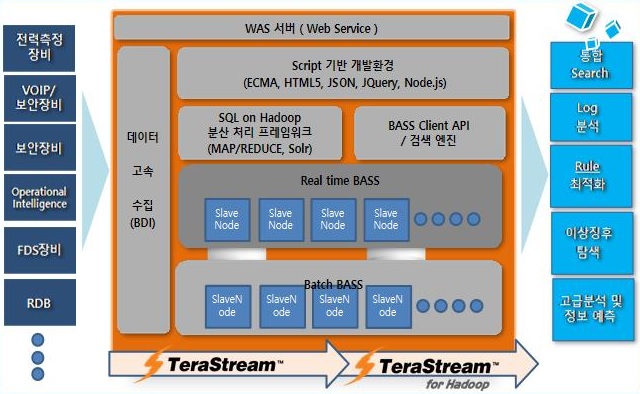
데이터스트림즈의 신성장동력 ‘테라스트림 바스’
데이터스트림즈는 데이터관리SW 전문기업으로, 자체 개발한 데이터 통합 및 데이터 품질 관리 솔루션을 공급하고 있다. 주력 제품인 ETL 툴 ‘테라스트림(TeraStream)’은 데이터 통합 시장에서 1위를 차지하고 있으며, 지난 2012년 이후부터는 DW 및 BI 분야로 사업을 확장하면서 다양한 데이터 기반 비즈니스를 아우르는 기업으로 변화하고 있다. 지난해에는 다양한 IoT 데이터를 실시간 분석하는 인메모리 기반 실시간 스트리밍 데이터 처리 플랫폼 ‘테라스트림 바스(TeraStream BASS)’를 출시하며 신성장동력 발굴에 나섰다.
‘테라스트림 바스’는 메모리 기반 분산저장 플랫폼으로, 인덱싱과 동시에 저장하는 아키텍처가 기반이 된다. 각종 솔루션 전문 분야를 탑재하기 위한 부분과 OLTP성 FDS 또는 운영 인텔리전스 처리를 지원하며, 웹서버를 탑재해 고급 분석 및 정보 예측 분야를 지원한다. 150바이트(byte) 기준 1개 노드당 초당 200만 건의 저장속도, 60ms(밀리초)의 검색속도, PB급까지 속도가 유지되는 검색 용량을 제공한다.
| |
 |
|
| ▲ 데이터스트림즈 ‘테라스트림바스’ 구조 |
특히 정형은 물론 반정형·비정형까지 다양한 데이터를 메모리에 빠르게 저장해 실시간으로 분석할 수 있게 해주며, 시각화 구현방식의 유연성과 고객사 구축환경에 따른 커스터마이징을 지원한다. 과거 데이터는 메모리에서 HDFS(하둡분산파일시스템)로 내리는데, MR(맵리듀스) 관련 알고리즘을 자체적으로 개선해 이 데이터에 대한 관리성능이 향상된 것도 특징이다. ‘테라스트림’과의 호환성도 좋아 기존 RDB의 데이터도 원활하게 활용할 수 있다.
‘테라스트림 바스’는 실시간 빅데이터 기반 전력 감시 및 분석, 보안장비 로그 분석, 실시간 서버장비 이벤트 로그 분석, 실시간 IDC 센터 관제 및 모니터링, VOIP 이상징후 검색, 각종 센서 데이터 실시간 로그 분석, 빅데이터 기반 실시간 빌딩 에너지 최적화, 실시간 도로위험기상정보 생산 위한 관측, 공장 설비 데이터 실시간 분석, 실시간 통신 서비스 품질 분석, 제조업 공정라인 실시간 데이터 분석, MES 데이터 실시간 연계, 홈 서비스 장애 진단 시스템, IoT 융합 서비스 등에 적용해 활용 가능하다.
| [인터뷰] “더 빠르게, 더 다양하게, 더 편하게”
| |
 |
|
| ▲ 정현규 데이터스트림즈 이사 |
테라스트림 바스, 어디에 쓰이나.
‘테라스트림 바스’는 실시간 빅데이터 분석 및 감시 솔루션을 제공하는 메모리 기반 플랫폼으로, IoT를 겨냥한 실시간 분석 시스템이다. 다양한 데이터를 빠르게 수집해 메모리 분산 저장 장치에 저장하고, 오래된 데이터는 하둡의 HDFS에 분산 저장 처리하는 하이브리드 분석 기능을 제공한다. 감시, 예측, 의사결정, 경고, 모니터링, 관제 등 조회 및 분석 성격의 업무에 주로 사용되며, 공공과 금융 분야 위주로 문의가 오고 있다.
데이터스트림즈의 향후 계획은.
공공기관 및 기업에서 신규 빅데이터 분석 플랫폼 구축과 시범서비스 또는 파일럿(pilot)구축사업, 그리고 기 구축 플랫폼의 고도화와 서비스 확장사업이 공공기관 위주로 많이 진행되고 있다. 데이터스트림즈는 고유의 데이터통합 및 데이터 거버넌스, 메모리 처리기술을 기반으로 하둡 등 오픈소스 기술을 접목해 빅데이터 분석플랫폼 솔루션으로 국내는 물론 해외시장에 집중할 계획이다. 또한 앞으로 반정형·비정형데이터 관리 분야도 선점해나갈 방침이다. |
이디엄의 간편한 제안 ‘로그프레소’
이디엄은 지난 2013년 세 명의 공동창업자가 설립한 스타트업이다. 이들은 설립 이전인 2008년부터 로그데이터 처리 기술을 함께 연구해왔으며, 현재 이디엄은 ‘실시간 역인덱스 생성 및 검색 기술’, ‘이벤트 처리시스템의 이벤트 처리방법’ 등의 특허를 보유하고 있다. 설립과 함께 출시한 ‘로그프레소(LogPresso)’는 ‘로그데이터의 핵심 의미를 에스프레소 커피머신처럼 빠르게 추출한다’는 뜻를 담은 실시간 빅데이터 분석 플랫폼으로, 올해 3.0버전 출시를 앞두고 있다.
5년여의 엔진 개발을 거쳐 출시된 ‘로그프레소’는 시계열 머신데이터에 대한 실시간 풀텍스트/필드 인덱싱 기술을 지원, 1년 이상 운영하더라도 데이터 누적에 의한 성능 저하가 일어나지 않는다. 또한 실시간 데이터 수집, 분석, 저장, 시각화의 전 과정을 하나의 솔루션에서 구현한 점이 특징이다. 일반적으로 스트림 엔진과 쿼리 엔진은 별개 제품이지만, ‘로그프레소’는 이 두 가지가 결합돼 높은 유연성과 성능을 제공한다.
| |
 |
|
| ▲ 이디엄 ‘로그프레소’ 구조 |
아울러 이벤트 연관 분석을 수행할 수 있도록 자체 CEP 엔진이 내장돼 FTP, SFTP, HDFS, JDBC 등 다양한 외부 리소스를 스트림에서 조인할 수 있으며, 별도 개발 없이 모든 ETL 작업이 쿼리로 가능하다. 필드 암호화 및 테이블 단위 암호화까지 자체적으로 지원하며, 이러한 모든 기능이 통합돼 있으므로 데이터와 목적이 분명하다면 당일 분석을 시작할 수 있을 정도로 간편하게 구축할 수 있는 것이 강점이다.
더불어 사용성 측면에서도 드래그앤드롭으로 다양한 위젯을 배치해 대시보드를 구성할 수 있고, 웹 관리화면에서 수집 설정부터 시각화까지 전 과정을 수행할 수 있다. 페더레이션 기반 분산처리를 지원하며, 최소한의 하드웨어 장비로 운영 가능한 비용효율성과 간단한 구성에 따른 관리편의성도 제공한다.
| [인터뷰] “경험에서 우러나온 사용자 중심 솔루션”
| |
 |
|
| ▲ 구동언 이디엄 COO |
로그프레소, 어디에 쓰이나.
‘로그프레소’는 대용량의 정형·비정형데이터를 수집, 검색, 분석, 시각화해 신속한 의사결정을 돕는 솔루션이다. 기존의 RDB로는 쏟아지는 로그를 처리하는데 한계를 느껴 개발하기 시작했고, 2009년부터 2년간 보안 스타트업 엔초비를 할 때도 꾸준히 개발해왔다. 현재 경쟁사 대비 최소 3배 이상 높은 인덱싱 처리 및 검색 성능을 제공하고, 평균적으로 6배 이상 적은 하드웨어 장비를 필요로 한다. 0.5초 이내 실시간 응답요건을 충족해야 하는 FDS(이상거래탐지)를 비롯해 LTE통신로그분석과 보안관제 등에 쓰이고 있다.
이디엄의 계획은.
‘로그프레소’를 현업에서 더 쓰기 편하게 발전시키고자 한다. 데이터 파싱 및 정규화의 어려움을 해결해주고, 스트림에 대한 멀티노드 로드밸런싱이나 페일오버가 가능하도록 개발하려 한다. 사용자 정의 분석 화면 설계, 클릭을 이용한 데이터 분석 지원, 인터랙티브 드릴다운 분석, 사용자 정의 보고서 출력 등도 계획하고 있다. 장기적으로는 클라우드 기반 데이터 처리 플랫폼으로 서비스하는 것을 염두에 두고 있다. 내년부터는 글로벌 시장 공략도 본격적으로 시작할 예정이다. |
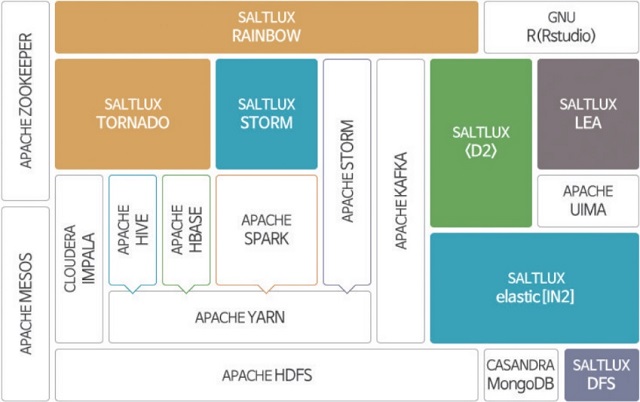
솔트룩스의 전략적인 행보 ‘D2’
솔트룩스는 정형·비정형데이터 융합·분석과 인공지능(시맨틱) 기술 기반의 B2B 솔루션 사업 및 클라우드 컴퓨팅 기술을 접목한 B2C 소셜서비스를 제공하고 있다. GS인증 등 다양한 인증과 수상, 80건의 특허 출원 및 31건의 등록 특허 등 다수의 지적재산권을 보유하고 있으며, 배트남 개발센터를 포함해 일본, 중국 지사뿐만 아니라 미국, 유럽 등 전 세계적으로 사업 및 연구개발 파트너를 확보하고 있다.
솔트룩스는 10년 전부터 대규모 비정형데이터 또는 통신데이터, 유럽과의 R&D 사업, 센서 및 IoT 관련 공동연구 사업을 추진해오면서 시장 변화를 감지해 실시간 데이터 분석 플랫폼 ‘D2’를 비롯한 모든 아키텍처와 기술을 발전시켜왔고, 시맨틱 검색과 텍스트마이닝을 넘어 빅데이터 기반 기계학습과 온톨로지 기반 추론을 융합한 스마트데이터 제품과 빅데이터 검색·분석 솔루션을 선보이게 됐다고 밝혔다.
| |
 |
|
| ▲ 솔트룩스 ‘빅O’ 구조 |
‘D2’는 ▲단일 서버에서 초당 5만 건 이상의 실시간 스트림 빅데이터 처리 ▲정형·비정형 빅데이터의 융합 분석 ▲시계열 패턴 감지를 포함한 실시간 패턴 감지와 CEP ▲집합연산, 고급 통계 분석과 개체명 인식 및 감성분석 등 강력한 실시간 분석 질의어 ▲예측과 자동 알림 기능 ▲실시간 시각화와 R 연동 등을 주요 특징으로 내세우고 있다. 텍스트, 트위터, 기업 내부 문서, 이메일 등 비정형데이터를 실시간 분석할 수 있고, 고객의 사용목적에 맞게 커스터마이징 가능하고 비용효율적으로 제공되는 것이 장점이다.
솔트룩스는 오픈소스와 결합된 ‘빅O(BigO)’ 플랫폼도 선보이고 있다. 얀(YARN)을 포함한 하둡뿐 아니라 ‘아파치 스파크’, 실시간 스트림 데이터 처리를 위한 ‘스톰(STORM)’과 UIMA 프레임워크를 ‘IN2’, ‘D2’, 솔트룩스 ‘스톰’ 등과 통합 구성함으로써 대용량, 실시간 데이터의 수집, 저장, 검색과 병렬/분산 분석 및 시각화 등의 기능을 하나의 플랫폼에 구현했다는 설명이다.
| [인터뷰] “이제는 스마트데이터 시대”
| |
 |
|
| ▲ 이경일 솔트룩스 대표 |
D2, 어디에 쓰이나.
솔트룩스는 빅데이터와 인공지능 기술을 결합한 특징을 갖고 있고, 비정형 빅데이터 분석 및 시맨틱 기술을 기반으로 국내외 다양한 빅데이터 및 검색 프로젝트의 80% 이상을 구축해왔다. 실시간 분석 시장도 궁극적으로 머신데이터뿐 아니라 휴먼데이터와의 융합 분석으로 발전하리라 보고 있으며, ‘D2’에도 이를 위한 기술이 반영됐다. 주로 보안 및 안보 분야에서 쓰이고 있으며, 스마트팩토리와 IoT 관련 분야에도 빠르게 적용되고 있다.
솔트룩스의 향후 계획은.
그간 수집과 저장 관련 이슈에 다소 치우쳐있던 빅데이터 시장이 이제 빠르게 변화하고 있다. 향후 2~3년 내로 빅데이터에 인공지능을 적용한 스마트데이터가 실질적인 가치를 만들며 주목받을 것이다. 자사는 이를 위해 기계학습과 딥러닝의 결합을 통한 예측 분석 기술 개발에 집중할 계획이다. 또한 DaaS(Data as a Service) 서비스 사업을 지속 확장해나갈 예정으로, 분석 클라우드 서비스 ‘O2’의 확장 버전인 ‘데이터 믹시(DATA MIXI)’ 서비스도 준비 중이다. 2020년에는 세계 10대 지식서비스 기업이 되는 것이 목표다. |
|
|
reference : http://www.itdaily.kr/news/articleView.html?idxno=68224
Oracle 2015. 4. 8. 11:11
| | OPN 혜택 및 리소스 | Silver | Gold | Platinum | Diamond | | 파트너 환영 키트 | | | | | | 안전한 OPN 파트너 웹 사이트 액세스 | | | | | | 자료실 컨텐츠의 제한적 이용 | Cloud Services, 1-Click 및 Oracle Database Appliance 자료실 | | | | | 파트너 뉴스레터 | | | | | | Oracle Partner Business Center | | | | Global Diamond Desk | | 전화를 통한 파트너 관리 지원1 | | | | | | 전담 오라클 파트너 비즈니스 컨설턴트 | | | | | | Oracle OpenWorld에서 파트너 포럼 및/또는 라운지에 참가하여 솔루션 소개2 | | | | | | 세일즈 부문 부사장/경영진 후원자와의 미팅에 초대 | | | | | | 파트너 자문 위원회 참가2 | | | | | | 경영진 파트너 포럼 참가2 | | | | | | Partner Award 수상 자격1 | | | | | | Global Alliance Manager 지정 | | | | | | 오라클 경영진 후원 | | | 지역별 | 글로벌 | | 역량 강화 혜택 및 툴 | Silver | Gold | Platinum | Diamond | | 파트너 전용 온라인 세미나, 선별된 이벤트와 워크숍 참석2 | | | | | | Oracle University의 e러닝 컨텐츠 라이브러리 액세스 | | | | | | Competency Center에서 제공하는 지침 학습 과정(GLP)을 통한 파트너별 교육 이용1 | Cloud Services, 1-Click 제품 및 Oracle Database Appliance | | | | | Enablement 2.0 Boot Camp1 | Cloud Services, 1-Click 제품 및 Oracle Database Appliance | | | | | Oracle University 제품 및 서비스에 대한 할인1 | 20% | 25% | 25% | 25% | | OPN 멤버쉽 가입 또는 갱신 후 처음 30일 이내에 구입하는 Oracle University 학습 크레딧에 대한 할인 | 35% | 35% | 35% | 35% | | OPN 멤버쉽 가입 또는 갱신 후 처음 30일 이내에 구입하는 SSCD(Self-Study CD)에 대한 할인 | 35% | 35% | 35% | 35% | | 라이브 가상 강의(LVC)에 대한 할인1 | 20% | 25% | 30% | 30% | | 시험 바우처에 대한 할인 | 20% | 25% | 25% | 25% | | 무료 평가/시험 바우처1 | | 2 | 6 | 6 -100(Worldwide 파트너) | | 개발 혜택 및 툴 | Silver | Gold | Platinum | Diamond | | 테크놀로지 프로그램에 대한 개발 라이센스5 | 1-Click 제품 및 Oracle Database Appliance | 에 나와 았음 | 에 나와 았음 | 에 나와 았음 | | Oracle Validated Integration | | 수수료 방식 | 할인 | 할인 | | SOA 기반의 Oracle Validated Integration1 | | 수수료 방식 | 1개 포함 | 1개 포함 | | 오라클 제품으로의 마이그레이션을 지원하기 위한 리소스(툴 키트, 워크벤치 및 타사 마이그레이션 제공업체)1 | | | | | | 사전에 베타 프로그램 신청 가능 | | | | | | 마케팅 혜택 및 툴 | Silver | Gold | Platinum | Diamond | | Oracle.com/events에 파트너 이벤트 게시 가능 | | 전문화된 기술력과 솔루션을 갖춘 경우 | | | | 오라클 파트너 브랜드 및 로고 사용1 | | | | | | Oracle.com에 소개1 | | | | | | Oracle Cloud Marketplace에 게시 신청4 | | | 우선 홍보 기회 | 우선 홍보 기회 | | 마케팅 키트1 | Cloud Services, 1-Click 제품 및 Oracle Database Appliance | | | | | 오라클 출판물 광고비 할인(인쇄 및 디지털) | 25% | 35% | 40% | 50% | | 오라클 관련 정보를 심층적으로 다룬 뉴스레터 후원에 대한 할인 혜택 | 25% | 35% | 40% | 50% | | 마케팅 캠페인을 위한 연락처 목록 액세스1 | | | | | | MDF(Marketing Development Funds) 신청1 | | | | | | 전담 글로벌 파트너 마케팅 관리자 | | | | | | 공동 고객 성공 사례에 대한 전문적인 개발1 | | | | | | Oracle Magazine의 파트너 뉴스 섹션에서 홍보1 | | | | | | 홍보(PR) 지원 및 가이드라인1 | | | 공동 보도 자료 | 공동 보도 자료 | | Oracle Cloud Marketplace 또는 AppCloud Marketplace에 승인된 통합에 대한 보도 자료 게시4 | | | | | | Google 애드워즈 캠페인의 오라클 상표 | | | | | | JavaONE 및 Oracle OpenWorld에서 솔루션 소개1 | | | | | | 오라클 고객을 직접 만나는 자리에서 연설1 | | | | | | 오라클 내부용 활동에서 연설할 수 있는 기회4 | | | | | | 판매 혜택 및 툴 | Silver | Gold | Platinum | Diamond | | 각 자료실에 나와 있는 멤버쉽 레벨 및 리셀러 자격 조건 달성에 따라 공인된 오라클 제품 및 서비스 판매1 | 1-Click 제품 및 Oracle Database Appliance | | | | | 오라클 프로그램 및 서비스 판매를 위한 OPN 멤버 할인 가격1 | 1-Click 제품 및 Oracle Database Appliance | | | | | 세일즈 키트1 | Cloud Services, 1-Click 제품 및 Oracle Database Appliance | | | | | OMM 정책에 따라 결정되는 Oracle Open Market Model(OMM) Resale Initiative를 통해 순 신규 영업 기회 등록1 | | | | | | OMM 정책에 따라 결정되는 OMM Referral Initiative를 통해 오라클 비즈니스를 추천하는 경우 보상1 | | | | | | Oracle OMM Non-commission Co-Sell Initiative를 통해 오라클 영업 기회를 등록하는 경우 인지도 강화1 | | | | | | 고객에게 Oracle Financing 제공1 | | | | | | 테크놀로지 및 애플리케이션 프로그램을 위한 데모 라이센스5 | 1-Click 제품 및 Oracle Database Appliance | 에 나와 았음 | 에 나와 았음 | 에 나와 았음 | | Oracle PartnerNetwork Solutions Catalog를 통해 가시성 확보1 | | | 우선 배치 및 홍보 | 우선 배치 및 홍보 | | Oracle PartnerNetwork Solutions Catalog를 통해 영업 기회 창출1 | | | | | | 내부용으로 사용할 오라클 프로그램 라이센스 구입 시 할인1 | | | | | | 내부용으로 사용할 CRM On-Demand 프로그램 라이센스 구입 시 할인1 | | | | | | 비즈니스 실무 및 가격 정보 교육1 | | | | | | 국제적인 부패 방지 교육1 | | | | | | 지원 혜택 및 툴 | Silver | Gold | Platinum | Diamond | | Oracle Solaris, Solaris Cluster 및 Solaris Studio 업데이트 및 패치 이용5 | | | | | | OPN SI(Support IdentifierI)를 통해 "My Oracle Support" 이용5 | 1-Click 제품 및 Oracle Database Appliance | | | | 소프트웨어 업그레이드 및 패치
(테크놀로지 및 애플리케이션 제품만 해당) - 현 오라클 지원 제품 및 릴리스5 | 1-Click 제품 및 Oracle Database Appliance | | | | | Partner Business Center의 지원 서비스 | 1-Click 제품 및 Oracle Database Appliance | | | | | 특별 파트너 할인 가격으로 SR(Service Request) 패키지 구입1 (테크놀로지 및 애플리케이션 제품만 해당) | | | | | | 개발, 데모 및 통합 라이센스와 함께 사용할 무료 SR(Service Request)1 | | | | | | Enterprise Linux Basic Support 서비스 및 Oracle VM Premier Support 서비스를 통해 무료 SR을 사용하여 파트너의 Linux 및 Oracle VM 개발 시스템 지원1 | | | | | | Linux Basic Support 서비스 및 Oracle VM Premier Support 서비스를 위한 패치/업데이트를 다운로드하여 OPN 멤버의 Linux 및 Oracle VM 개발 시스템 지원 | | | | | | 파트너의 Linux 및 Oracle VM 개발 시스템을 위한 Linux 및 Oracle VM 지원 서비스 가격 할인1 | | | | | | OCVS(Oracle Collaborative Vendor Support) 프로그램 이용1 | | | | | | 파트너 내부용으로 사용할 ACS(Advanced Customer Services)에 대한 할인1 | Linux 및 VM 전용 | | | | | ACS(Advanced Customer Services) 파트너 팀에 대한 개별적 액세스1 | | | | | | ACS의 혜택에 대한 보완적 컨설팅1 | | | | | | ACS(Advanced Customer Services) 내부 웹 페이지에 대한 OPN 멤버 노출1 | | | | | | 공동 캠페인을 위한 ACS(Advanced Customer Services)의 공동 마케팅 및 영업 기회 창출 지원1 | | | | |
유효한 ASFU/ESL 협약을 체결한 OPN 멤버를 위한 기술 지원 SR(Service Request) 및 확장된 지원 패키지8 | | | | | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready 및 Oracle Exastack Optimized와 관련된 혜택 및 툴 | Silver | Gold | Platinum | Diamond | | 새로운 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready 및 Oracle Exastack Optimized 알림 및 오리엔테이션 통지1 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | | 안전한 OPN 전문화 리소스 센터 이용 | | 전문화 프로그램 | 전문화 프로그램 | 전문화 프로그램 | | Oracle Exastack Optimized 로고 | | Oracle Exastack Optimized | Oracle Exastack Optimized | Oracle Exastack Optimized | | OPN 전문화(Specialized) 로고1 | | 전문화 프로그램 | 전문화 프로그램 | 전문화 프로그램 | | Oracle Exastack Ready 로고 | | Oracle Exastack Ready | Oracle Exastack Ready | Oracle Exastack Ready | | Oracle Validated Integration 로고 | | Oracle Validated Integration | Oracle Validated Integration | Oracle Validated Integration | | OPN 고급 전문화 프로그램 로고 | | 고급 전문화 프로그램 | 고급 전문화 프로그램 | 고급 전문화 프로그램 | | 뉴스레터, 웹 사이트, 광고 등으로 홍보1 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | | OPN Solutions Catalog에 우선 배치 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | | 오라클의 내부 파트너 찾기 시스템에 우선 배치1 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | | 내부 뉴스레터에 발표1 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | | 무료 시험 바우처1 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | | 보도 자료에 오라클 경영진의 인용구 사용1 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | | 오라클 회의실 시설 이용1 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | | 데모 서비스 이용1, 4 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized / 우선 이용 | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized / 우선 이용 | 무료 지원 SR(Service Request)
(테크놀로지 및 애플리케이션 제품만 해당)1, 3 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | | Enterprise Linux Basic Support 서비스 및 Oracle VM Premier Support 서비스를 통해 무료 지원 SR(Service Request)로 파트너의 Linux 및 Oracle VM 개발 시스템 지원1, 3 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | | 제품 릴리스 준비 자료1 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | | 구현 방법 이용1 | | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized | 전문화 프로그램, Oracle Validated Integration, Oracle Exastack Ready, Oracle Exastack Optimized |
|
위에 열거된 OPN 혜택은 OPN 정책, OPN 협약 및 해당하는 모든 부록 또는 개정 조항의 조건에 의거하여 OPN 멤버에게 제공됩니다. 지역별 제한 사항에 따라 혜택의 제공 여부가 다를 수 있습니다. 혜택이 오라클의 독자적인 판단에 따라 제공된다고 이 혜택 표에 나와 있는 경우 해당 혜택의 제공 여부에 관한 오라클의 결정이 최종 결정이 됩니다.
미국 및 캐나다: 미국 및 캐나다 지역에서 활동하는 파트너는 전문화 자격을 얻기 위해 공공 부문 기관과의 거래를 포함시킬 수 있습니다. 그러나 공공 부문 기관과의 거래는 거래 건수, 매출, 기타 세일즈 기반의 메트릭 등을 토대로 제공되는 전문화 영역 또는 Oracle PartnerNetwork 멤버쉽과 관련된 혜택(전문화 상태 및 관련 로고 사용 이외)을 결정하는 데는 포함되지 않습니다. 공공 부문은 정부, 입법/의사결정 기구, 사법기관, 정부대행기관, 정부부처, 국가/지방/시 단위의 국가행정기관, 정부가 관리하거나 대부분의 지분을 소유하고 있는 공기업, 정당이나 정치조직 등과 같은 공공기구나 재단, 국제 적십자사나 UN, 세계은행 등과 같은 국제기구, 공립 대학교, 공립 초/중/고등학교, 공공 보건 기관 등의 공공 부문 기관 등을 말합니다. 전문화된 기술력과 솔루션을 갖춘 오라클 파트너에게 제공되는 혜택과 툴의 제공 여부는 OPN 정책에 따라 결정됩니다.
Oracle PartnerNetwork 멤버는 혜택 제공 중지 정책을 반드시 검토하십시오.
오라클은 독자적인 판단에 따라 언제든지 OPN 혜택 표 중 잘못되거나 누락된 부분을 수정할 수 있는 권리를 갖습니다.
2009년 11월 또는 그 이후에 OPN 전문화 프로그램으로 마이그레이션하지 않은 파트너는http://www.oracle.com/ocom/groups/public/@opnpublic/documents/webcontent/019737.pdf에 명시된 혜택을 받을 수 있습니다.
각주: - 본 혜택은 미국 정부 기관(연방, 주 및 지역 정부, 공익 사업체 및 고등 교육 기관 포함) OPN 멤버에게는 제공되지 않습니다.
- 미국 정부 기관(연방, 주 및 지역 정부, 공익 사업체 및 고등 교육 기관 포함) OPN 멤버는 본 혜택을 이용하기 전에 관할 법률 또는 윤리 담당자의 승인 증명을 Political Compliance의 Oracle Director에게 제공해야 합니다.
- 이 혜택은 OPN 정책에 따라 (a) 공공 부문 기관과의 거래 및/또는 (b) 공공 부문 기관의 고객 레퍼런스를 사용하여 비즈니스 조건을 충족하는 방식으로 전문화된 기술력과 솔루션을 갖춘 파트너 입지를 확보한 미국 또는 캐나다의 OPN 멤버에게는 제공되지 않습니다.
- 이러한 혜택을 이용하려면 추가 조건을 충족해야 합니다. 조건에 대한 자세한 설명을 검토하십시오.
- 이 혜택은 MOS(My Oracle Support)에 적용되지 않습니다. 자세한 내용은 오라클 소프트웨어 기술 지원 정책과 오라클 하드웨어 및 시스템 지원 정책을 참조하십시오.http://oracle.com/contracts.
|
|
reference : http://www.oracle.com/partners/campaign/specialized-benefits-036151-ko.html
|











