|
|
IT News 2016. 2. 22. 10:41
vim가 있으면 대부분의 프로그래밍이 가능하다. vim습득 하는데 시간이 걸린다는게 안좋은점이다. 에이터 플러그인 - neocomplcache.vim
- quickrun.vim
- vimproc + quickrun
- unite.vim
MacVimEmacsVIM, Emacs는 특별 하다라는 느낌이네요 에디터 플러그인 CocoaEmacsMouMarkdown를 쓰기위한 에디터 SublimeText2CotEditor무료. 완전 가벼운 에디터.
간단한 문장 수정에 적합하다. Coda쉐어. 에디터+IDE 같은 느낌. 디자인을 확인하면서 편집이 가능하다.FTP,SSH,SVN등도 함께 쓸수 있어서 디자이너에게는 이걸로 충분. TextWranglerEspressoEspresso 는 리얼타임으로 CSS를 프리뷰하면서 쓸수 있는 에디터. JSON Editor간단하게 JSON을 조작하는 에디터.
IDE(종합개발환경)XcodeiPhone어플을 개발할 마음이 없어도 넣어두면, 서로 차이가 나는 소스를 간단하게 다룰수 있는 FileMerge어플이랑opendiff코멘드등 덤으로 붙어 있기 때문에 추천 EclipseEclipse나NetBeans등 우선 사용하는 파. 그래서 어느쪽이 좋은지를 결정하는거보다 '이건 뭐가 뛰어나지?'를 보고, 경우에 따라서 바꿔 가며 쓰자. http://www.eclipse.org/ NetBeansEclipse나NetBeans등 우선 사용하는 파. 그래서 어느쪽이 좋은지를 결정하는거보다 '이건 뭐가 뛰어나지?'를 보고, 경우에 따라서 바꿔 가며 쓰자. PhpStromPHP나JavaScript를 시작하는 웹 프로그래머용 IDE。 Cloud9아직 조잡하지만, 브라우저에서 실행할수 있는IDE. GitHub나Bitbucket등과 연동 WebStorm현재 IDE중에서는 JavaScript 부분의환경이 최고. 자매품 PHPStorm도 평가가 좋다,
내부 소스 프로그램 수정,버그 수정등이 간단하게 되지만, 유료 입니다. 써볼만한 가치는 있다고 생가갑니다... Nidenode.js IDE
SQL, DBSequel Pro MySQL클라이언트. phpMyAdmin가 필요없어 졌다. NavicatMySQL클라이언트 MySQLWorkbenchEER그림도 그릴수 있기때문에 데이터 베이스 설계에도 사용할수있음. HeidiSQLWindows용 MySQL클라이언트 인데요,HeidiSQL
JDBC/ODBC등없이 이거 하나로 접속 가능하며, 스프레드 시트를 순차적으로 열어가는 형태의 브라우징이 가능하다. 그렇기 때문에 "실제 DB데이터를 보면서 데이터를 조작한다" 라는 점이 직감적으로 가능해, 매우 편리. SSH터널 접속, 서버 간의 데이터 덤프 & 리스토어도 가능하기 때문에 , 운영 작업은 거의 이걸로 완결.
단, 좀 불안정하기 때문에 , 거의 멈추지 않는 작업에는 적합하지 않을지도...
(그런건 서버에서 해! 라고 한소리 들을것 같네요) adminerphpMyAdmin랑 같은 브라우저 베이스의 DB클라이언트. 1파일에서php가 움직이는 환경이라면 OK, 무엇보다도 가볍기 때문에 편하게 자주 쓰고 있다.
MySQL,PostgreSQL, SQLite, MS SQL,Oracle랑 의외로 무슨 SQL이든 사용이 가능한데 어째서인지 마이너. SQLEditorER도 작성 툴. 생SQL나ActiveRecord Model를 출력할수있다. Base.appSQlite용 GUI관리 툴. ERMasterDB관리 툴。
Eclipse의 플러그인인데, DB관리+도큐멘트화가 엄청나게 편해진다. The SQLite SorcererSQLite용 클라이언트. AIR제. PHPMAMP xhprofphp 로 쓰여진 Web어플리케이션 병목지점을 조사할때 필수 xdebugPHPUnit사용할수 있는 테스트 프레임 워크가 이것 밖에 없음 Phingphp 의 빌드 툴,테스트 환경이나 본방 환경등의 환경을 환경채로 부트스트랩 지시나, 종합 테스트 설정에 쓰임
RubytravisCI 계속 통합 bundler어플리케이션 마다 필요한 Gem 을 관리 할수있다. 디플로이 장소 구축에 편리 Capistrano디플로이,PHP 든지 다르 언어로 쓰여진 어플리 케이션도 설정에 따라서 이걸로 디플로이 가능 Pryirb에서 갈아 탐. watchrguardgist
JavaJavaDecompilerJavaScriptnode.jsJavaScript의 대화 실행 환경, 어쨋든 빠르게 JS의 동작 체크 하고싶을때 편리 SpiderMonkeyJavaScript의대화 실행 환경 어쨋든 빠르게 JS동작을 체크하고 싶을때 ringo.jsJavaScript의대화 실행 환경 어쨋든 빠르게 JS동작을 체크하고 싶을때 jsPerfJavaScript의 벤치 마크를 얻을수 있는 사이트. js 벤치마크를 얻어서 공개하는데 편리. jsFiddle브라우저내에서 JavaScript 실행・HTML/CSS의 마크업 같은게 가능하다 Google Closure CompilerJavaScript를 압축할 일이 있으면 、Google Closure Compiler YUI CompressorJavaScript도 CSS도 압축할 일이 있으면 、YUI Compressor impress.jsenchant.jsnpmforevercoffee-scriptrvmnvmnavePythonpypypython에서 쓴 프로그램이 좀 느리다고 생각하면 일단 한번 사용해 본다(django가 움직이기 때문에 관계가 있지요?) virtualenv, virtualenvwrapper, pythonbrewpython이라 하면 virtualenv, virtualenvwrapper。최근에는 pythonbrew을 쓴다 SimpleHTTPServerPython라면、SimpleHTTPServer가 편한거 같습니다. pipipythonscipywerkzeugCSS, HTML, LESSLess.appLESS을 쓸일이 있으면 LESS.app도 편리함. Twitter Bootstrap자신은 프로그램에 집중 하고싶다, 나름대로 멋도 있는게 좋다 라는 경우에는 Twitter Bootstrap로 템플릿을 간단하게 작생해 두면 좋을지도. zen-codingHTML/CSS의 입력 지원. IDE가 지원 하거나、에디터에 플러그인으로 넣을수 있다.
테스트xUnit계XUnitTestPatterns든지 읽어두면 어느 언어의 xUnit계의 테스트 프레임 워크도 이해하기 쉬워짐 xSpec계JBehave이나 RSpec이나. PHP에는 없음.Wikipedia영어판BDD가 알기 쉽다. QuickCheck계프로그램 구조 그대로 기술해서,랜덤으로 인수를 부여서해서 검증하는 테스트 프레임 워크.
오리지널은 Haskell부터인데,메이저 언어 에서도 이미 꽤 사용중.
Haskell 이외의 언어에서 의욕적으로 쓸수있도록 개발하고있는YelloSoft 가 알기 쉬울지도
네트워크Hosterhosts파일을 GUI로 설정하는 어플. wiresharkwireshark, tshark는 사용방법만 외워두면 초 강력. HTTP ClientMockSMTP가상 로컬SMTP. 인터넷에 연결되지 않아도 SMTP로 동작을 체크가능 FTP, SSH, SCP~/.ssh/config: SSH주변 설정을 정리해두면 엄청 편리PuTTYWindowsのSSH는 PuTTY파 이지만、다른 사람에게 추천하는건 Poderosa PoderosaWindowsのSSH는 PuTTY파 이지만、다른 사람에게 추천하는건 Poderosa ClusterSSHTransmit리모트 한 상태에서 파일을 더블 클릭하면 파일을 로컬에 보존→열림、파일 보존→자동적으로 업로드등이 가능, 간단한 개발에는 꽤 편리. 그리고 접속 하는쪽 디렉토리를 Finder에 마운트 할수있는 공포의 기능등. 물론 ssh도 대응 greprakRuby계의 툴 rak 코멘드. grep검색 툴. ackbetter than grep jvgrep자화자찬 인데요,grep로jvgrep. go언어로 쓰여져 있기때문에 linux에서도 windows에서도 똑같이 동작.
일본어 엔코딩은 거의 지원해주고 있고, 여러가지 엔코딩 파일이 섞여있을때의 grep등, 통칭 쓸때없는 문자를 포함한 정규표현에도 올바르게 움직입니다.(한국어도 있나 싶어서 검색해봤지만 딱히 눈에 띄이진 ㅇ Tipsexport GREP_OPTIONS='--color=auto'
에서fgrep/egrep/grep했을때에 매치했을때 단어가 컬러로 하이라이트 되도록 표시 된다 grep/fgrep/egrepの-o 옵션. 매치한 단어만 유출 할수있다, 이것은 한줄로 완성된 프로그램을 쓸때 사용할수 있다.egrep은 확장정규표현 이기때문에 Perl이든지 Ruby같은 편리한 정규표현을 사용할수있다. fgrep은 고정 문자열검색할때 빠른다.
詳細: http://d.hatena.ne.jp/lurker/20070131/1170201200 통계처리수만건 정도의 로그를 간단하게 처리하고 싶을때 편리
중앙값, 표준편차등도 한방에 구할수 있다. 데이터를 기준으로 히스토그램, 3D그래프등 ROctave터미널TotalTerminalMac의 터미너를 바로가기키로 바로 불러낼수 있습니다. iTerm2percolpercol 가 터미널로 사용할수 있는 범용적이고 편리한 툴입니다. 어떻게 사용하는지에 따라 지식/센스등을 시험받는 기분이 듭니다.
SubversionCornerstoneSVN클라이언트 VersionsSVN클라이언트 gitSmartGit (Windows)Git 클라이언트 SourceTree (Mac)Git 클라이언트 GitHub자신이 쓴 소스코드를 공개 tiggit를 사용할거라면 tig가 없으면 살아갈수없다. GitXTowergithub for mac브라우저SRWare IronUserAgent를 바꿀수있는 Chrome같은 사용방법으로 쓸수있다.
패키지관리MacPorts프리. 패키지 관리 툴. 컴파일에 시간이 걸리지만 옛날부터 사용하고 있기떄문에 손 놓을수 없는 툴. HomebrewUNIX의 코멘드등을 간단하게 사용할수 있다. 그외 개발 툴codekitCodeKit automatically compiles Less, Sass, Stylus, CoffeeScript & Haml files. pandoc적으면서 모은 markdown메모를
도큐멘트로 만들때에 pandoc을 사용해서html화 한다. Integrity고속 링크체커. 디플로이 전의 필수 아이템 Omnigraffle쉐어 . 도큐멘트 작성 툴. 이걸로 사용서를 만들때 엄청 빠르게 끝낼수 있음. osx-gcc-installerMac에서「xcode는 필요없지만, gcc만은 원해」라고 생각했을때 죽을만큼 고마운 툴. 우선 Watch 나 즐찾 VMware + Gentoo (or Ubuntu, Debian, etc)ImageOptim이미지 파일을 경량화 HTML서버로서의 DropboxHTML+CSS+JS를 글로벌 액세스로 디버그 할려고 생각하면, 결국 Dropbox의Public 폴더가 가장 간단한 하다는걸 깨달았습니다.(스마트폰용 사이트 등) 그외 작업 효율화 관계 툴CaffeineBetterTouchToolClipMenuLimechat for mac osxPreferences -> Log -> Show image links in inline을 사용함으로 바꾸면
유저명에 대응한 영상을 Twitter에서 가져와서 인라인으로 전개해준다.
물론 틀린 프로필 이미지가 전개 되는경우도 있지만, 유명한 사람이 많은IRC같은거라면 대체로 맞다 QuickSilverQuicksilverは、어플리케이션을 실행시켜、컴퓨터 ・파일조작、e-mail 임시저장과 송신과 같은 작업을 키보드로 빠르게 처리 할수있다. Quixquix 편리하지만 사용하는 사람을 본적이없다. SkitchLingon프리 or 쉐어。자동 기동 관리 툴. OSX의 자동기동 프로그램을 시각적으로 편집하거나 할수있다. Growl기본적인 곳의 Mac이라면 Growl AlfredQuickSilver같은 fuzzy 같은 문자열에 의한、어플리케이션 검색 & 실행 런처. QuickSilver보다도 좋은점은、매치 하는 어플리케이션가 없을때는 구글 검색해준다는 점. ReederRSS리더는 Reeder를 추천. CinchMac에서 간단하게 가면을 2분할(Win7의 그것)을 해주는 툴. FluidWeb어플을 간단하게 로컬어플리화 할수있는 녀석. Web어플로 간단하게 개발해서、클라이언트를 브라우저로 하지 않거나 항상 상주 시키고 싶을때에 편리. DIVVY화면을 핫키 한방에 분할 할수있다. A Better Finder RenameRENAME가 초 간단 Skim경량 PDF리더。Adobe Acrobat보다 좋은거같다. BeanMicrosoft Word보다도 쾌적 Unix/Linux/Macコマンド- gdb
- lv
- xargs
- iotop
- htop
- iperf
- htop
- zsh
- tree
- make
- bison
- awk
서버에서 장기간 걸리는 작업을 불안정한 회선등으로 할때에 특별히 도움이 됩니다. screen은 간단하게 프로센스를 오래 살도록 하는데에 편리합니다.
ssh에서 접속해서 무언가 시간이 걸리는 프로세스를 실행해도 접속을 끊으면 프로세스도 커널에 종료되어버리는데
거기에서 screen안에서 프로세스를 기동해서、screen을 deattached해두면、그 프로세스는 오래살수있도록 할수있습니다.
. 처음에 고맙다라고 생각한게 서버위에서 장시간 작업할때
통신가 툭 끊어져도 screen의 프로세스 자체는 살아남기 때문에, 다시한번 서버에 접속해서
남아있는 screen의 프로세스에 attached하면 작업이 즉시 재개 시킬수 있습니다. vim의 작업 상태 등도 그대로 남아 있습니다.
byobu라는것은 screen가 좋은느낌으로 커스텀마이즈 된 녀석
screen/tmux 가 다가가기 힘든 사람에게는 byobu가 추천입니다.
우선 곤란해 하지 않을 설정이 기본적으로 되어져 있습니다.
나머지는 밑의 많은t ips
"terminal multiplexor Advent Calendar 2011 : ATND" http://atnd.org/events/22320 . 네이티브의 바이너리 관련、od,file,nm,strings,strace,varglind
. 개인적으로는 vim/zsh/screen。이 3개는 어떤 환경이라도 반드시 넣는다
. find ./ -name *.php | xargs grep hoge とかはよく使いますね。Windowsは秀丸のgrepが強力です。
git, 자주 사용하는 코멘드랑 옵션http://qiita.com/items/2047#comment-2182 추운날에 CPU가 발열해서 따듯해지는 코멘드추운날은 충전중의 맥북에서 ruby -r digest/sha1 -e 'loop{Digest::SHA1.hexdigest(Time.now.to_f.to_s)}'
같은걸 하면 잠깐 방치하면 마음대로 CPU가 발연해서 따듯해짐 미분류mscgensequence도를 쓸거라면 mscgen를 추천
cheatyUMLUML을 그리고 출력할수 있는 Web서비스. 유닉크한 URL가 발행되기 때문에 블로그에 붙이거나 가능 클래스 /액티비티 /유즈 케이스 WebSequenceDiagrams.comUML을 그리고 출력할수 있는 Web서비스. 유닉크한 URL가 발행되기 때문에 블로그에 붙이거나 가능 시퀀스 도 http://www.websequencediagrams.com/ CacooAppleK for VMwareMac에서 가상 머신 위의 Windows를 사용하는 경우에는 키 조작이 Mac과 같으되도록 설정해주는 어플. 유료지만 VM위에서의 작업효율이 크게 올라가기 때문에 추천
- VMWare용
http://www.trinityworks.co.jp/software/AppleKforVMware3/index.php
- Parallels용
http://www.trinityworks.co.jp/software/AppleKforParallels3/index.php KeyRemap4Macbook왜인지 아직 거론되지 않는 KeyRemap4Macbook. 키 분배를 자유럽게 커스텀마이즈 할수있음、같은 키를 길게 눌렀을때나 키가 입력되기전까지 기다리는 시간을 표준 보다 고속화 할수있다. Mac을 사용하는 프로그래머에게 있어선 많이 쓰는 어플.
http://pqrs.org/macosx/keyremap4macbook/index.html.ja BitNami다양한 OSS플랫폼/어플을 인스톨러를 사용해서 간단하게 도입할수 있게해주는 소프트 http://bitnami.org/stacks AMPPS다양한 OSS플랫폼/어플을 인스톨러를 사용해서 간단하게 도입할수 있게해주는 소프트
http://www.ampps.com/ TEKICO일본어・영문자 더미 문자를 생각하는 AIR제품 소프트. Web사이트의 프론트 타이프 작업할때에 활용.
출처 : http://tkdwnsdkk.tistory.com/101
IT News 2016. 2. 16. 13:23
그 동안 제 블로그에서 많이 인용되는 글 중 하나가 바로 "쉽게 배우는 하둡 에코 시스템(http://blrunner.com/18)"인데요. 작성한 지 3년이 넘어가는 글이라서 최근 동향에 맞게 다시 정리를 해봤습니다. 
[그림]하둡 에코시스템
코디네이터
- Zookeeper(http://zookeeper.apache.org)
분산 환경에서 서버 간의 상호 조정이 필요한 다양한 서비스를 제공하는 시스템으로, 크게 다음과 같은 네 가지 역할을 수행합니다. 첫째, 하나의 서버에만 서비스가 집중되지 않게 서비스를 알맞게 분산해 동시에 처리하게 해줍니다. 둘째, 하나의 서버에서 처리한 결과를 다른 서버와도 동기화해서 데이터의 안정성을 보장합니다. 셋째, 운영(active) 서버에 문제가 발생해서 서비스를 제공할 수 없을 경우, 다른 대기 중인 서버를 운영 서버로 바꿔서 서비스가 중지 없이 제공되게 합니다. 넷째, 분산 환경을 구성하는 서버의 환경설정을 통합적으로 관리합니다.
리소스 관리
- YARN(http://hadoop.apache.org) 얀(YARN)은 데이터 처리 작업을 실행하기 위한 클러스터 자원(CPU, 메모리, 디스크등)과 스케쥴링을 위한 프레임워크입니다. 기존 하둡의 데이터 처리 프레임워크인 맵리듀스의 단점을 극복하기 위해서 시작된 프로젝트이며, 하둡2.0부터 이용이 가능합니다. 맵리듀스, 하이브, 임팔라, 타조, 스파크 등 다양한 애플리케이션들은 얀에서 리소스를 할당받아서, 작업을 실행하게 됩니다. 얀에 대한 자세한 설명은 http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/index.html을 참고하시기 바랍니다.
- Mesos(http://mesos.apache.org) 메소스(Mesos)는 클라우드 인프라스트럭처 및 컴퓨팅 엔진의 다양한 자원(CPU, 메모리, 디스크)을 통합적으로 관리할 수 있도록 만든 자원 관리 프로젝트입니다. 메소스는 2009년 버클리 대학에서 Nexus 라는 이름으로 시작된 프로젝트이며, 2011년 메소스라는 이름으로 변경됐으며, 현재는 아파치 탑레벨 프로젝트로 진행중이며, 페이스북, 에어비엔비, 트위터, 이베이 등 다양한 글로벌 기업들이 메소스로 클러스터 자원을 관리하고 있습니다. 메소스는 클러스터링 환경에서 동적으로 자원을 할당하고 격리해주는 매커니즘을 제공하며, 이를 통해 분산 환경에서 작업 실행을 최적화시킬 수 있습니다. 1만대 이상의 노드에도 대응이 가능하며, 웹 기반의 UI, 자바, C++, 파이썬 API를 제공합니다. 하둡, 스파크(Spark), 스톰(Storm), 엘라스틱 서치(Elastic Search), 카산드라(Cassandra), 젠킨스(Jenkins) 등 다양한 애플리케이션을 메소스에서 실행할 수 있습니다.
데이터 저장
- HBase(http://hbase.apache.org)
H베이스(HBase)는 HDFS 기반의 칼럼 기반 데이터베이스입니다. 구글의 빅테이블(BigTable) 논문을 기반으로 개발됐습니다. 실시간 랜덤 조회 및 업데이트가 가능하며, 각 프로세스는 개인의 데이터를 비동기적으로 업데이트할 수 있습니다. 단, 맵리듀스는 일괄 처리 방식으로 수행됩니다. 트위터, 야후!, 어도비 같은 해외 업체에서 사용하고 있으며, 국내에서는 2012년 네이버가 모바일 메신저인 라인에 HBase를 적용한 시스템 아키텍처를 발표했습니다.
- Kudu(http://getkudu.io) 쿠두(Kudu)는 컬럼 기반의 스토리지로서, 특정 컬럼에 대한 데이터 읽기를 고속화할 수 있습니다. 물론 기존에도 HDFS에서도 파케이(Parquet), RC, ORC와 같은 파일 포맷을 사용하면 컬럼 기반으로 데이터를 저장할 수 있지만, HDFS 자체가 온라인 데이터 처리에 적합하지 않다는 약점이 있었습니다. 그리고 HDFS 기반으로 온라인 처리가 가능한 H베이스의 경우, 데이터 분석 처리가 느리다는 단점이 있었습니다. 쿠두는 이러한 문제점들을 보완하여 개발한 컬럼 기반 스토리지이며, 데이터의 발생부터 분석까지의 시간을 단축시킬 수 있습니다. 클라우데라에서 시작된 프로젝트이며, 2015년말 아파치 재단의 인큐베이션 프로젝트로 선정됐습니다.
데이터 수집
- Chukwa(http://chukwa.apache.org)
척와(Chuckwa)는 분산 환경에서 생성되는 데이터를 HDFS에 안정적으로 저장하는 플랫폼입니다. 분산된 각 서버에서 에이전트(agent)를 실행하고, 콜렉터(collector)가 에이전트로부터 데이터를 받아 HDFS에 저장합니다. 콜렉터는 100개의 에이전트당 하나씩 구동되며, 데이터 중복 제거 등의 작업은 맵리듀스로 처리합니다. 야후!에서 개발했으며, 아파치 오픈소스 프로젝트로 공개돼 있습니다.
- Flume(http://flume.apache.org)
플럼(Flume)은 척와처럼 분산된 서버에 에이전트가 설치되고, 에이전트로부터 데이터를 전달받는 콜랙터로 구성됩니다. 차이점은 전체 데이터의 흐름을 관리하는 마스터 서버가 있어서 데이터를 어디서 수집하고, 어떤 방식으로 전송하고, 어디에 저장할지를 동적으로 변경할 수 있습니다. 클라우데라에서 개발했으며, 아파치 오픈소스 프로젝트로 공개돼 있습니다.
- Scribe(https://github.com/facebook/scribe)
페이스북에서 개발한 데이터 수집 플랫폼이며, Chukwa와는 다르게 데이터를 중앙 집중 서버로 전송하는 방식입니다. 최종 데이터는 HDFS 외에 다양한 저장소를 활용할 수 있으며, 설치와 구성이 쉽게 다양한 프로그램 언어를 지원합니다. HDFS에 저장하려면 JNI(Java Native Interface)를 이용해야 합니다.
- Sqoop(http://sqoop.apache.org)
스쿱(Sqoop)은 대용량 데이터 전송 솔루션이며, 2012년 4월에 아파치의 최상위 프로젝트로 승격됐습니다. Sqoop은 HDFS, RDBMS, DW, NoSQL 등 다양한 저장소에 대용량 데이터를 신속하게 전송하는 방법을 제공합니다. 오라클, MS-SQL, DB2 등과 같은 상용 RDBMS와 MySQL, 포스트그레스큐엘(PostgreSQL)과 같은 오픈소스 RDBMS 등을 지원합니다.
- Hiho(https://github.com/sonalgoyal/hiho)
스쿱과 같은 대용량 데이터 전송 솔루션이며, 현재 깃헙(GitHub)에 공개돼 있습니다. 하둡에서 데이터를 가져오기 위한 SQL을 지정할 수 있으며, JDBC 인터페이스를 지원합니다. 현재는 오라클과 MySQL의 데이터 전송만 지원합니다.
- Kafka(http://kafka.apache.org) 카프카(Kafka)는 데이터 스트림을 실시간으로 관리하기 위한 분산 메세징 시스템입니다. 2011년 링크드인에서 자사의 대용량 이벤트처리를 위해 개발됐으며, 2012년 아파치 탑레벨 프로젝트가 됐습니다. 발행(publish)-구독(subscribe) 모델로 구성되어 있으며, 데이터 손실을 막기 위하여 디스크에 데이터를 저장합니다. 파티셔닝을 지원하기 때문에 다수의 카프카 서버에서 메세지를 분산 처리할 수 있으며, 시스템 안정성을 위하여 로드밸런싱과 내고장성(Fault Tolerant)를 보장합니다. 다수의 글로벌 기업들이 카프카를 사용하고 있으며, 그중 링크드인은 하루에 1조1천억건 이상의 메세지를 카프카에서 처리하고 있습니다.
데이터 처리
- Pig(http://pig.apache.org)
피그(Pig)는 야후에서 개발됐으나 현재는 아파치 프로젝트에 속한 프로젝트로서, 복잡한 맵리듀스 프로그래밍을 대체할 피그 라틴(Pig Latin)이라는 자체 언어를 제공합니다. 맵리듀스 API를 매우 단순화한 형태이고 SQL과 유사한 형태로 설계됐습니다. SQL과 유사하기만 할 뿐, 기존 SQL 지식을 활용하기가 어려운 편입니다.
- Mahout(http://mahout.apache.org)
머하웃(Mahout)은 하둡 기반으로 데이터 마이닝 알고리즘을 구현한 오픈소스 프로젝트입니다. 현재 분류(classification), 클러스터링(clustering), 추천 및 협업 필터링(Recommenders/collaborative filtering), 패턴 마이닝(Pattern Mining), 회귀 분석(Regression), 차원 리덕션(Dimension reduction), 진화 알고리즘(Evolutionary Algorithms) 등 중요 알고리즘을 지원합니다. Mahout을 그대로 사용할 수도 있지만 각 비즈니스 환경에 맞게 최적화해서 사용하는 경우가 많습니다.
- Spark(http://spark.apache.org)
스파크(Spark)는 인메모리 기반의 범용 데이터 처리 플랫폼입니다. 배치 처리, 머신러닝, SQL 질의 처리, 스트리밍 데이터 처리, 그래프 라이브러리 처리와 같은 다양한 작업을 수용할 수 있도록 설계되어 있습니다. 2009년 버클리 대학의 AMPLab에서 시작됐으며, 2013년 아파치 재단의 인큐베이션 프로젝트로 채택된 후, 2014년에 탑레벨 프로젝트로 승격됐습니다. 현재 가장 빠르게 성장하고 있는 오픈소스 프로젝트 중의 하나이며, 사용자와 공헌자가 급격하게 증가하고 있습니다.
- Impala(http://impala.io)
임팔라(Impala)는 클라우데라에서 개발한 하둡 기반의 분산 쿼리 엔진입니다. 맵리듀스를 사용하지 않고, C++로 개발한 인메모리 엔진을 사용해 빠른 성능을 보여줍니다. 임팔라는 데이터 조회를 위한 인터페이스로 HiveQL을 사용하며, 수초 내에 SQL 질의 결과를 확인할 수 있습니다. 2015년말 아파치 재단의 인큐베이션 프로젝트로 채택됐습니다.
- Presto(https://prestodb.io) 프레스토(Presto)는 페이스북이 개발한 대화형 질의를 처리하기 위한 분산 쿼리 엔진입니다. 메모리 기반으로 데이터를 처리하며, 다양한 데이터 저장소에 저장된 데이터를 SQL로 처리할 수 있습니다. 특정 질의 경우 하이브 대비 10배 정도 빠른 성능을 보여주며, 현재 오픈소스로 개발이 진행되고 있습니다.
- Hive(http://hive.apache.org)
하이브(Hive)는 하둡 기반의 데이터웨어하우징용 솔루션입니다. 페이스북에서 개발했으며, 오픈소스로 공개되며 주목받은 기술입니다. SQL과 매우 유사한 HiveQL이라는 쿼리 언어를 제공합니다. 그래서 자바를 모르는 데이터 분석가들도 쉽게 하둡 데이터를 분석할 수 있게 도와줍니다. HiveQL은 내부적으로 맵리듀스 잡으로 변환되어 실행됩니다.
- Tajo(http://tajo.apache.org)
타조(Tajo)는 고려대학교 박사 과정 학생들이 주도해서 개발한 하둡 기반의 데이터 웨어하우스 시스템입니다. 2013년 아파치 재단의 인큐베이션 프로젝트로 선정됐으며, 2014년 4월 최상위 프로젝트로 승격됐습니다. 맵리듀스 엔진이 아닌 자체 분산 처리 엔진을 사용하며, HiveQL을 사용하는 다른 시스템들과는 다르게 표준 SQL을 지원하는 것이 특징입니다. HDFS, AWS S3, H베이스, DBMS 등에 저장된 데이터 표준 SQL로 조회할 수 있고, 이기종 저장소간의 데이터 조인 처리도 가능합니다. 질의 유형에 따라서 하이브나 스파크보다 1.5 ~ 10배 빠른 성능을 보여줍니다.
워크플로우 관리
- Oozie(http://oozie.apache.org)
우지(Oozie)는 하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템입니다. 자바 서블릿 컨테이너에서 실행되는 자바 웹 애플리케이션 서버이며, 맵리듀스 작업이나 피그 작업 같은 특화된 액션으로 구성된 워크플로우를 제어합니다.
데이터 시각화
- Zeppelin (https://zeppelin.incubator.apache.org) 제플린(Zeppelin)은 빅데이터 분석가를 위한 웹 기반의 분석 도구이며, 분석결과를 즉시 표, 그래프로 제공하는 시각화까지 지원합니다. 아이파이썬(iPython)의 노트북(Notebook)과 유사한 노트북 기능을 제공하며, 분석가는 이를 통해 손쉽게 데이터를 추출, 정제, 분석, 공유를 할 수 있습니다. 또한 스파크, 하이브, 타조, 플링크(Flink), 엘라스틱 서치, 카산드라, DBMS 등 다양한 분석 플랫폼과 연동이 가능합니다. 2013년 엔에프랩의 내부 프로젝트로 시작됐으며, 2014년 아파치 재단의 인큐베이션 프로젝트로 선정됐습니다.
데이터 직렬화
- Avro(http://avro.apache.org)
RPC(Remote Procedure Call)와 데이터 직렬화를 지원하는 프레임워크입니다. JSON을 이용해 데이터 형식과 프로토콜을 정의하며, 작고 빠른 바이너리 포맷으로 데이터를 직렬화합니다. 경쟁 솔루션으로는 아파치 쓰리프트(Thrift), 구글 프로토콜 버퍼(Protocol Buffer) 등이 있습니다.
- Thrift(http://thrift.apache.org) 쓰리프트(Thrift)는 서로 다른 언어로 개발된 모듈들의 통합을 지원하는 RPC 프레임워크입니다. 예를 들어 서비스 모듈은 자바로 개발하고, 서버 모듈은 C++로 개발되었을때, 쓰리프트로 쉽게 두 모듈의 통신 코드를 생성할 수 있습니다. 쓰리프트는 개발자가 데이터 타입과 서비스 인터페이스를 선언하면, RPC 형태의 클라이언트와 서버 코드를 자동으로 생성합니다. 자바, C++, C#, Perl, PHP, 파이썬, 델파이, Erlang, Go, Node.js 등과 같이 다양한 언어를 지원합니다.
출처 : http://blrunner.com/99
IT News 2016. 1. 18. 12:44
출처 : MIT OpenCourseWare YouTube 교수 : Eric Grimson, John Guttag 제 01강 - 연산이란 - 데이터 타입, 연산자 및 변수 소개 제 02강 - 연산자와 피연산자 - 분기문, 조건문 그리고 반복문 제 03강 - 공통 코드 패턴, 반복 프로그램 제 04강 - 기능을 통한 분해 및 추상화, 재귀 소개 제 05강 - 부동 소수점, 계통적 명세화, 루트 찾기 제 06강 - 이분법, 뉴턴/랩슨, 그리고 리스트 소개 제 07강 - 리스트와 가변성, 딕셔너리, 의사코드, 그리고 효율성 소개 제 08강 - 복잡성 - 로그, 선형, 이차 방정식, 지수 연산 알고리즘 제 09강 - 이진 탐색, 버블 그리고 분류 선택 제 10강 - 분할 정복 방법, 합병 정렬, 예외 제 11강 - 테스트와 디버깅 제 12강 - 디버깅 추가 강의, 배낭 문제, 동적 프로그래밍 소개 제 13강 - 동적 프로그래밍 - Overlapping subproblems, Optimal substructure 제 14강 - 배낭 문제 분석, 객체 지향 프로그래밍 소개 제 15강 - 추상 데이터 타입, 클래스와 메소드 제 16강 - 캡슐화, 상속, 쉐도잉 제 17강 - 연산 모델 - 랜덤워크 시뮬레이션 제 18강 - 시물레이션 결과 제시, Pylab, Plotting 제 19강 - 편향된 랜덤워크, 배포 제 20강 - 몬테카를로(Monte Carlo) 시뮬레이션, 추정 파이 제 21강 - 시뮬레이션 결과 검증, 곡선 적합, 선형 회귀 제 22강 - 일반, 균등 그리고 지수 분포 - 통계의 오류 제 23강 - 주식 시장 시뮬레이션 제 24강 - 과정 개요 - 컴퓨터 과학자들은 무엇을 하나요?
IT News 2015. 11. 10. 16:55
구글에서 Deep learning Library를 Open Source화 하였군요.
자세한 내용은 첨부된 내용들을 보면 될 것 같아요.
Python과 C++ 으로 Library 사용 가능~
소프트웨어 라이센스는 apache 2.0 입니다. 공개된 소스 코드를 이용해서 상업적인 프로그램을 개발하여 재패포 가능!!
TensorFlow Mechanics 101
The goal of this tutorial is to show how to use TensorFlow to train and evaluate a simple feed-forward neural network for handwritten digit classification using the (classic) MNIST data set. The intended audience for this tutorial is experienced machine learning users interested in using TensorFlow.
These tutorials are not intended for teaching Machine Learning in general.
Please ensure you have followed the instructions to Install TensorFlow.
Tutorial Files
This tutorial references the following files:
| File |
Purpose |
mnist.py |
The code to build a fully-connected MNIST model. |
fully_connected_feed.py |
The main code, to train the built MNIST model against the downloaded dataset using a feed dictionary. |
Simply run the fully_connected_feed.py file directly to start training:
python fully_connected_feed.py
Prepare the Data
MNIST is a classic problem in machine learning. The problem is to look at greyscale 28x28 pixel images of handwritten digits and determine which digit the image represents, for all the digits from zero to nine.

Download
At the top of the run_training() method, the input_data.read_data_sets() function will ensure that the correct data has been downloaded to your local training folder and then unpack that data to return a dictionary of DataSet instances.data_sets = input_data.read_data_sets(FLAGS.train_dir, FLAGS.fake_data)
NOTE: The fake_data flag is used for unit-testing purposes and may be safely ignored by the reader.
| Dataset |
Purpose |
data_sets.train |
55000 images and labels, for primary training. |
data_sets.validation |
5000 images and labels, for iterative validation of training accuracy. |
data_sets.test |
10000 images and labels, for final testing of trained accuracy. |
For more information about the data, please read the Download tutorial.
Inputs and Placeholders
The placeholder_inputs() function creates two tf.placeholder ops that define the shape of the inputs, including the batch_size, to the rest of the graph and into which the actual training examples will be fed.images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,
IMAGE_PIXELS))
labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size))
Further down, in the training loop, the full image and label datasets are sliced to fit the batch_sizefor each step, matched with these placeholder ops, and then passed into the sess.run() function using the feed_dict parameter.
Build the Graph
After creating placeholders for the data, the graph is built from the mnist.py file according to a 3-stage pattern: inference(), loss(), and training().
inference() - Builds the graph as far as is required for running the network forward to make predictions.loss() - Adds to the inference graph the ops required to generate loss.training() - Adds to the loss graph the ops required to compute and apply gradients.
Detail Contents -->  Getting Started - TensorFlow.pdf Getting Started - TensorFlow.pdf
Reference URL : http://tensorflow.org/
IT News 2015. 11. 9. 16:52
[컴퓨터월드] 세상은 점점 더 빨라지고, 복잡해지고 있다. IT기술의 발전에 따라 데이터는 폭증하며 급류를 이루기 시작했고, 만물이 이어지는 초연결사회(Hyper-Connected Society)의 도래가 임박했다. 이러한 변화로 인해 경쟁마저 더욱 빠르고 복잡하게 전개되는 양상을 보인다. 치열해지는 경쟁에서 생존하기 위해서는 보다 빠르고 명확한 의사결정이 필수적이다. 이에 빅데이터 속에서 실질적인 인사이트를 실시간으로 얻는 것이 화두가 되고 있다.
최근 관련업계에서는 사물인터넷(IoT) 시대를 맞아 각종 기계로부터 쏟아지고 있는(machine-generated) 데이터에 대한 관심이 점차 늘어나고 있다. 사람들이 만들어내는(human-generated) 데이터와 달리, 기계는 끊임없이 정보를 쏟아내면서도 그 속에 거짓말은 찾을 수 없다. 이곳을 출발지로 삼으면서 실시간 빅데이터 분석 시장이 태동하고 있는 것이다. 각자 고유의 무기를 내세워 이 새로운 전장에 출사표를 던진 이들의 행보를 간단히 살펴본다.
IoT 시대, 분석거리가 쏟아진다
‘IoT’와 ‘분석’은 현재 가장 각광받고 있는 IT트렌드에 속한다. 시장조사기관 가트너는 지난해 말 ‘2015년 10대 전략 기술 동향’을 발표, 향후 3년간 기업에 주요한 영향을 미칠 가능성이 있는 기술들 가운데 이 두 가지를 선정했다. IoT 시대를 맞아 디지털화로 인해 생성되는 데이터 흐름과 서비스의 융합은 관리(manage), 현금화(monetize), 운영(operate), 확장(extend)이라는 네 가지 IoT 사용 모델을 창조, 모든 기업들은 산업과 무관하게 이 기본 모델을 활용해 디지털 비즈니스를 영위할 수 있게 됐다.
아울러 임베디드(embedded) 시스템이 생성하는 데이터의 양이 증가하고 기업 내외 정형·비정형 데이터 풀(pool) 분석이 가능해지면서 분석이 보편화되고 있다. 기업들은 IoT, 소셜 미디어, 웨어러블 기기에서 생성된 대량의 데이터를 적절히 분류, 알맞은 정보를 제때 필요한 곳에 정확히 전달하는 것을 과제로 안게 됐다. 이에 가트너는 분석 기술이 모든 곳에 내장돼 끝단에서 데이터가 처리되는 ‘엣지 애널리틱스(Edge Analytics)’가 대두될 것으로 보고 있다.
이러한 변화는 점차 가속화되고 있다. 시장조사기관 IDC는 오는 2018년까지 IoT에서 생성된 데이터의 40%가 보관되고 프로세스를 거쳐 분석될 것으로 예상했다. 또한 현재는 IoT의 50% 이상이 제조, 운송, 스마트시티 및 컨슈머 애플리케이션 분야에 집중돼있지만, 향후 5년 내 전 산업에서 IoT가 활성화될 전망이다. IDC는 기업들이 네트워크에 연결된 수많은 디바이스로부터 쇄도하는 데이터를 효과적으로 조율하기 위한 방안을 고심해봐야 한다고 강조했다.
IDC에 따르면, 글로벌 IoT 시장은 지난해 6,558억 달러에서 연평균 16.9% 성장, 오는 2020년에는 1조 7천억 달러 규모를 형성할 것으로 전망된다. 특히 한국을 비롯한 아시아·태평양지역(일본 제외)의 IoT 산업도 높은 성장세를 지속, 연결된 기기 및 사물(things) 대수가 31억 대에서 86억 대 규모로 증가할 것으로 내다봤다. 동기간 이 지역의 IoT 시장은 2,500억 달러에서 5,830억 달러 규모로 성장할 것으로 바라보고 있다.
기업이 관리하는 데이터 중 비정형데이터가 정형데이터보다 더 많아지고 있고, 빅데이터가 IoT와 결합하면서 웨어러블 시장 및 맞춤형 추천, 유통과 교통에 이르기까지 폭넓은 분야에 새로운 기술이 적용될 것으로 보인다. 지능적 보안 및 안보 분야에서도 실시간 모니터링과 리스크 감지 시장이 급격히 성장하고 있다. 특히 제조업 중심의 한국은 스마트팩토리 등 인더스트리 4.0 구현의 중요한 시장이 될 것이다.
실시간 분석 수요 확대
IoT 시대의 도래에 따라 빅데이터의 ‘실시간 분석’에 대한 니즈가 급증하고 있다. ‘온라인 분석’은 데이터의 생성 시점과 분석 시점의 구분이 없는 반면, ‘실시간 분석’은 데이터가 생성되는 시점에 최대한 가깝게 분석이 함께 이뤄진다. 이 ‘실시간’에 대한 기준은 업무 성격에 따라 분 단위, 초 단위, 1초 미만 등으로 다양하게 정의되고 있으나, 갈수록 이에 대한 요건이 다양화되는 동시에 강화되고 있는 추세다.
IoT 시대의 실시간 분석은 수많은 센서나 소셜미디어에서 생성되는 시계열(time series) 데이터를 그 대상으로 하며, 특히 각종 기계로부터 생성되는 로그데이터가 주재료가 되고 있다. 머신데이터는 빅데이터 중에서도 증가세가 가장 빠른 영역이며, 다양한 트랜잭션과 고객 행동, 센서 기록, 기계 설비 거동, 보안 위협, 사기 행위 등을 파악할 수 있다는 점에서 보다 빠르고 정확하게 실질적인 가치를 얻을 수 있다는 특징을 지녔다.
실시간 분석 솔루션을 표방하는 소프트웨어(SW) 기술들은 기존 OLAP(온라인분석처리) 영역의 분석용 데이터베이스관리시스템(DBMS)나 데이터웨어하우스(DW)와도 다소 차이를 보인다. 마치 라면을 조리할 시간과 여건이 부족할 때는 간단히 취식할 수 있는 컵라면을 찾는 것과 같다. 데이터를 분석하기 위해 ETL(추출·변환·적재)을 비롯한 여러 과정을 거쳐 DW에서 주기적으로 배치(batch) 처리할 필요 없이, 생성되는 데이터를 바로 처리하고 분석해 필요한 만큼의 인사이트를 빠르게 얻을 수 있는 것이다.
이러한 민첩성(agility)은 하둡(Hadoop)을 위시한 오픈소스 빅데이터 플랫폼과의 가장 큰 차이점이다. 하둡은 배치성 아키텍처를 근간으로 하므로 실시간성과는 동떨어져 있어, 인메모리(in-memory) 기술이 적용된 ‘아파치 스파크(Apache Spark)’ 등을 통해 이에 대한 보완도 진행되고 있다. 그러나 기업이 하둡에코시스템을 제대로 활용하기 위해 요구되는 대규모 컴퓨팅파워와 이를 유지관리하기 위해 필요한 고급인력은 결국 TCO(총소유비용)의 증가를 야기한다는 점에서 여전히 생각해볼 문제로 남는다. 더불어 실시간 분석 솔루션들은 짧은 구축기간, SQL 활용 등 사용성을 무기로 삼아 이 틈새를 공략하고 있다.
스트리밍 데이터를 메모리상에서 바로 연관분석을 수행하는 CEP(복합이벤트처리) 기술은 실시간 분석 솔루션과 상호보완적인 관계로 볼 수 있다. CEP 기술은 데이터의 저장 단계 전에 특정 로직을 통해 예외상황 등의 이벤트를 확인하고 처리하는 방식이므로, 저장된 데이터를 가공하거나 검색하는 기능이 없고 입력되는 데이터를 다루는 범위도 한계를 지니게 된다. 그러나 CEP 기술은 빠른 응답속도에 강점을 갖고 있어, 실시간 분석 솔루션의 앞단에 위치하거나 또는 내장돼 공존하며 시너지를 내는 것이 가능하다.
같은 목적, 다른 접근
실시간 분석 솔루션은 빠르게 성장하는 새로운 시장으로, 장차 우리에게 어떤 영향을 미치게 될 것인지 아직 가늠하기 어려운 부분도 있다. 그러나 현재까지의 활용사례는 빙산의 일각에 불과하다는 것이 업계의 중론이다. IT벤더들은 ‘빅데이터’와 ‘실시간’이라는 두 축을 모두 지원하기 위해 다양한 형태의 솔루션을 선보이며 시장을 공략하고 있다.
이러한 실시간 분석 솔루션은 공통적으로 빠른 색인(indexing)을 지원하며, 크게 컬럼형DBMS에서 파생된 유형과 로그처리시스템에서 발전된 유형으로 구분할 수 있다. 컬럼형DBMS에서 파생된 유형의 경우 DML(데이터조작언어) 가운데 수정(update)과 삭제(delete)를 지원하지 않는 대신 입력(insert)과 검색(select)을 위한 성능을 극대화시키는 등의 방식을 취한다. 로그처리시스템에서 발전된 유형의 경우 NoSQL DB처럼 스키마(schema)를 고정하지 않고 로(raw)데이터 자체를 실시간 인덱싱하고 향후 분석 대상을 재정의하는 스키마리스(schema-less) 형태로 저장한다.
이 같은 일률적인 기준으로 구분하기에는 적절치 못할 수 있으나, 컬럼형DBMS에서 파생된 솔루션으로는 ▲파스트림 ▲아이리스DB ▲인피니플럭스 등을 들 수 있고, 로그처리시스템에서 발전된 솔루션으로는 ▲스플렁크 ▲테라스트림 바스 ▲로그프레소 ▲D2 등을 꼽을 수 있다. IoT 시대의 실시간 빅데이터 분석 니즈를 고유의 방식으로 풀어가고 있는 이 솔루션들과 각사의 전략에 대해 알아본다.
경쟁사들도 인정한 스피드 DBMS ‘파스트림’
굿모닝아이텍이 국내 총판을 맡고 있는 ‘파스트림(ParStream)’은 병렬처리의 ‘Parallel’과 스트리밍 데이터의 ‘Streaming’을 조합해 만들어진 이름이다. 파스트림사는 지난 2008년 독일에서 설립돼 현재는 실리콘밸리에 본사를 두고 있으며, 대부분의 기술진들이 C++에 대한 세계 최고 수준의 기술력을 가진 R&D 전문 인력이다.
‘파스트림’의 시초는 창업자들이 이전에 진행했던 여행 패키지 관리 프로젝트였다. 독일은 여행사가 판매한 여행 패키지 서비스에 대해 모든 것을 책임지는 구조로, 기상 조건에 의해 결항된다거나 예기치 못한 상황이 일어나는 것을 실시간으로 조정하고 관리할 필요가 있었다. 수십억 건의 데이터를 대상으로 모든 서비스에 응답속도 3초 이내가 요구사항이었으나, 이를 충족하는 솔루션을 찾지 못했다. 그래서 이를 위해 독자적으로 새로운 시도를 꾀한 끝에 탄생한 결과물이 바로 ‘파스트림’이다.
| |
 |
|
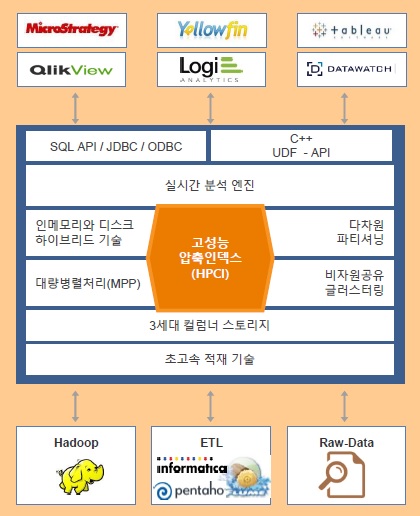
| ▲ ‘파스트림’ 구조 및 생태계 |
‘파스트림’ 분석플랫폼은 IoT와 빅데이터 환경의 대량 데이터를 초고속으로 처리할 수 있도록 개발된 컬럼형 DBMS로, 기존 DBMS나 DW시스템과는 추구하는 목적이 다르다. 기본적으로 OLTP(온라인트랜잭션처리)를 목적으로 하지 않기 때문에, 데이터의 업데이트와 딜리트 등을 지원하지 않고 빠르게 대량 인서트 및 스트리밍 데이터를 처리하면서 동시에 질의(쿼리)가 가능하도록 설계됐다. 실시간 분석을 지원하기 위해, 기존 DBMS에서 정합성을 보장하기 위한 고유 기술 중 하나인 록킹(locking) 메카니즘을 과감하게 제거한 제품이다.
MPP(대용량병렬처리) 및 인메모리 기술 등 기존의 검증된 기술을 채용해 대량의 데이터를 빠르게 처리할 수 있고, 나아가 HPCI(고성능압축인덱스)와 GDA(지역분산분석) 등의 고유 기술을 특징으로 삼고 있다. 대개의 경우 압축된 데이터를 메모리상에서 처리하기 위해서는 다시 압축을 풀어야 하지만, HPCI 기술은 압축을 풀지 않고도 가능하므로 기존 분석용 DBMS 대비 수십 배 빠르면서 더 적은 용량을 필요로 한다. 또 GDA 기술은 데이터를 중앙에 모아 처리할 필요 없이 지역별로 데이터 소스 가까이에서 실시간 분석과 저장을 지원, 가트너의 ‘엣지 애널리틱스’나 시스코의 ‘포그 컴퓨팅(Fog Computing)’을 구현할 수 있도록 돕는다.
‘파스트림’은 기하급수적으로 증가하는 IoT 빅데이터 처리 및 분석을 목적으로 순수하게 C++로 개발된 솔루션으로, 하둡 기술을 이용하지는 않았지만 분산처리 및 확장성에서는 일부 하둡 사상을 채용했다. 일반적인 RDBMS(관계형DBMS) 구조를 가지면서 표준 SQL을 지원하며, AWS(아마존웹서비스)를 비롯한 클라우드 환경에서도 ‘파스트림’을 사용할 수 있다. 다양한 기업들과 IoT를 위한 협업 생태계를 구축해 BI(비즈니스인텔리전스)나 ETL 등의 분야에서 기존 검증된 대부분의 솔루션을 연계 및 활용할 수 있는 것도 강점으로, 굿모닝아이텍과 함께 국내에서도 IoT 생태계 구축에 나서고 있다.
| [인터뷰] “혁신적인 기술로 차별화된 실시간 빅데이터 분석DB”
| |
 |
|
| ▲ 조외현 파스트림코리아 대표 |
파스트림, 어디에 쓰이나.
‘파스트림’은 필요 없는 기능들을 배제하고 실시간 IoT 빅데이터 분석에 특화된 DBMS라 가볍고 빠르다. 자동차로 비유한다면 세단이나 SUV가 아니라, 레이싱을 위한 스포츠카라고 할 수 있다. 기존 DBMS와는 달리 실시간으로 데이터를 분석해 인사이트를 얻을 수 있도록 최적화됐으며, 구조적인 한계를 지닌 로그관리시스템 등과는 달리 실제 대규모 데이터를 다양한 기법으로 처리할 수 있도록 지원한다. 무엇보다 간단하게 빅데이터 분석을 시작해볼 수 있다는 점이 매력이다.
초기에는 유통, 이커머스, 과학 분야 등에서 기존 업무를 대상으로 빅데이터를 빠르게 분석하기 위해 적용됐다. 최근에는 IoT 분야 적용사례가 급속히 늘고 있다. 대표적으로 중국 인비전에너지는 운영 중인 풍력발전기 2만대에 대한 실시간 분석 모니터링에 ‘파스트림’을 적용, 연간 1,700억 원에 달하는 효과를 거두고 있다. 또 옥토텔리매틱스는 운전자의 운전습관을 자동차보험과 접목해 사고예방은 물론 비용절감 효과를 거두고 있으며, 지멘스는 터빈당 5,000개의 센서를 통해 데이터를 수집·분석해 더욱 효율적인 가스터빈을 만드는데 활용하고 있다.
파스트림의 향후 계획은.
‘파스트림’은 신재생에너지 분야를 주도하는 유럽을 중심으로 활성화되고 있는 IoT 분야 적용사례를 확보하면서 분석플랫폼으로 자리매김하고 있고, 강점을 살릴 수 있는 IoT 시장과 실시간성 요건의 확대에 따라 앞으로의 전망도 밝다고 본다. 또한 IoT 분야는 너무 다양하기 때문에, 전문성 있는 기존 솔루션을 포용하는 협업생태계 전략을 취하면서 고객에게 확실한 신뢰와 장기적 비전을 제시하고 있다.
한편, 전 세계 빅데이터 시장규모를 보면 지난해 기준으로 순수 하둡이 전체 시장의 1% 미만으로 조사됐다. 전문가들은 2~3년 후도 이와 크게 다르지 않을 것이며, 컨설팅과 전문서비스 매출을 합해도 3% 정도가 될 것이라고 예측한다. 하둡이 빅데이터 시장 창출에 기여한 것은 사실이지만 활성화에는 한계를 보이고 있는 것으로, 이를 보완하기 위해 다양한 기술들이 개발되고 있으나 이들의 미래 또한 검증되지 않은 상황이다. 현재 빅데이터 분야는 춘추전국시대로, 이제는 국내에서도 맹목적인 글로벌 기술 추종과 시행착오에서 벗어나 보다 현실적인 대안을 검토할 필요가 있다고 본다. |
모비젠의 IoT 빅데이터 DB 어플라이언스 ‘아이리스DB’
지난 2000년 설립된 모비젠은 창사 이래로 대규모 통신망 및 네트워크 관리, 대용량 데이터 및 트래픽 처리에 기술을 쌓아온 기술 주도형 벤처다. 장기간 누적된 대용량 데이터 처리 및 분석 능력을 기반으로 빅데이터 처리 솔루션 및 망수준의 관리운용 솔루션(품질관리, 장애관리, 보안관리)을 공급하고 있다.
회사의 주요 고객 가운데 이동통신사가 포함되는 모비젠은 통신망의 발전에 따라 빠르게 증가하는 데이터 트래픽을 분석하기 위해 필연적으로 대용량 빅데이터 시스템을 구축, 실제적인 통신망의 요구에 부응하기 위해 빅데이터 분석 솔루션을 개발하게 됐다. 경쟁이 치열한 이동통신사들의 데이터 분석 요구는 항상 시장을 선도하는 것으로, 이에 대응하는 솔루션을 만드는 것이 필요했다. 이에 따라 PB(페타바이트) 수준의 대규모 데이터를 준실시간으로 모니터링하기 위한 데이터 분석 플랫폼 ‘아이리스DB(IRIS DB)’를 선보였다.
어플라이언스 형태로 공급되는 ‘아이리스DB’는 겉보기에는 기존 OLAP 영역의 DBMS 제품들과 별반 다르지 않지만, 급속도로 발전하는 이동통신환경에서의 통신데이터 처리에 초점을 맞춰 개발돼 일일 100 TB(테라바이트)에 이르는 데이터를 분 단위로 처리 및 분석 가능한 것이 강점이다. 주로 네트워크 모니터링에 사용되며, 보안관제에 쓰이기도 한다.
| |
  |
|
| ▲ 모비젠 ‘아이리스DB’ 구조 |
‘아이리스DB’는 메모리와 디스크를 모두 활용하는 하이브리드 방식으로, 메모리를 마치 파일시스템처럼 쓸 수 있게끔 구현됐다. 메모리에 데이터를 우선적으로 저장하면서 시간이 지나면 디스크로 보내는 구조로, 100% 메모리상에서 처리된다. 특히 인서트 성능을 극대화하기 위해 PB 규모의 데이터도 1 GB(기가바이트) 단위로 나눠 저장되는 점이 특징이다. 이를 통해 실시간 색인을 지원, IT운영에 필수적인 장애 대응과 품질 관리에 적합하도록 설계됐다.
‘아이리스DB’는 분산 환경에서의 데이터 처리를 위한 SQL을 대부분 지원해 추가적인 교육을 필요로 하지 않고, 단기간에 비용효율적으로 구축 가능하다. 최근에는 ‘아파치 스파크’를 통합, 하둡을 사용하고 있는 기존 고객들에게 편의를 더했다. 실시간 SQL 성능과 함께 장기간의 SQL 및 배치성·대화형 SQL 성능까지 향상시켰고, 대규모 빅테이블에 대한 조인(JOIN) 연산을 포함한 모든 SQL 분석 작업이 가능해져 기존 단일 DBMS 기반 레거시(legacy) 시스템을 대규모 분산 병렬화하는 작업에도 활용할 수 있게 됐다.
향후 모비젠은 세계적으로 앞서있는 국내 통신망 환경에서의 경험을 바탕으로 글로벌 시장 공략에 박차를 가할 계획이며, 주요 타깃은 중국과 일본 등 아시아 시장이다. 아울러 고급분석(Advanced Analytics)에 대한 고객들의 니즈에 부응, 그간 SI(시스템통합) 성격으로 진행해오던 기계학습(머신러닝) 관련 요소를 더욱 발전시켜 솔루션 형태로 상용화하는 것을 목표로 하고 있다.
| [인터뷰] “실시간성, 비용효율성, 사용편의성 고루 갖춰”
| |
 |
|
| ▲ 김형근 모비젠 연구소장 |
아이리스DB, 어디에 쓰이나.
모비젠은 머신데이터 분야에 초점을 맞추고 있으며, 높은 QoS(서비스품질)를 요구하는 곳의 실시간 데이터 관리에 최적화돼있다. 특히 높은 실시간성, 확실한 확장성, 풀 텍스트 검색, SQL 지원 등 국내 기업 환경에서 필요로 하는 핵심 요소들을 골고루 제공하고 비용효율적으로 구축할 수 있다는 것이 특장점이다. 대규모 머신데이터가 들어오는 곳 어디든 배치해 DB로 쓸 수 있고, 스토리지로도 쓸 수 있다.
‘아이리스DB’는 주로 통신망 관리, 보안관제 등에 사용된다. LTE망 품질관리, 대규모 보험사의 IT시스템 데이터 유출 모니터링 시스템 구축에 활용된다. 모든 패킷을 검사해 데이터 과금을 관리하는 이동통신사에서 ‘아이리스DB’를 활용, 기존 ‘오라클 엑사데이타’의 부하를 현저히 줄여준 사례도 있다. 향후 대량의 머신데이터가 빠르게 늘어날 것이라 예측되므로, ‘아이리스DB’와 같은 실시간 머신데이터 분석용 플랫폼을 찾는 수요는 더 많아질 것이다.
모비젠의 향후 계획은.
하둡으로 촉발된 빅데이터 기술이 아직 시장에서 완전히 안정화되지 않았다. 빅데이터 도입은 곧 하둡 도입으로 당연시했던 상황에서, 점차 고객들이 그 복잡도, 성능저하, 용량의 압박 등을 경험하고 있다. 고객사 중 국내 모 게임사의 경우 하둡에서 분산 빅데이터DB 도입으로 방향을 전환하려 하고 있다. 본격적인 빅데이터 분석 플랫폼 도입은 아직 시작되지 않았다고 볼 수 있다. 앞으로 하둡의 한계가 시장에 알려지면, 자연스럽게 솔루션형 빅데이터DB 시장이 열릴 것으로 기대하고 있다.
시간은 우리 편이라고 생각한다. 데이터의 증가와 실시간 분석의 요구는 필연적으로 빅데이터DB의 도입으로 귀결될 것으로 보인다. 주로 기존에 DW를 구축했던 곳의 DW 업그레이드 과제를 주 타깃으로 삼고 있다. DW의 용량확장, 백업·아카이빙 시 급증하는 비용을 ‘아이리스DB’가 효과적으로 해결해줄 수 있기 때문이다. 대규모 IT시스템 구축과제에서는 DBMS를 필수적인 부품처럼 도입하듯, 앞으로는 빅데이터DB도 거의 모든 프로젝트에서 도입하게 될 것이다. ‘아이리스DB’의 시장은 빠르게 넓어질 것으로 기대하고 있다. |
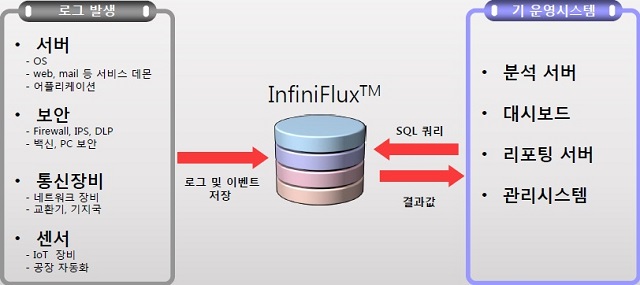
새롭게 등장한 시계열 빅데이터 DBMS ‘인피니플럭스’
김성진 전 알티베이스 대표가 지난 2013년 설립한 인피니플럭스(InfiniFlux)는 빅데이터 가운데 센서나 머신으로부터 발생하는 시계열 데이터를 실시간으로 저장하고 처리할 수 있는 DBMS를 전문적으로 개발하는 벤처기업이다. 기존 DBMS에서 처리하지 못하던 대량의 실시간 데이터를 새로운 아키텍처를 기반으로 분석할 수 있는 솔루션을 개발하는데 초점을 맞추고 있다.
전통적인 DBMS들은 트랜잭션 처리를 위해 ACID(원자성·일관성·고립성·지속성)를 만족해야 하는 제약사항이 있어 안정적이고 일관성 있는 데이터 처리에 주안점을 뒀으나, 최근 들어 폭증하는 수많은 센서 및 머신 데이터를 적절하게 처리하고자 하는 요구가 많아지고 있다. 이에 인피니플럭스는 전통적인 DB기술과 실시간 빅데이터 처리 기술을 결합, 기존 DB처럼 조작하면서도 실시간 시계열 데이터 처리에 특화된 새로운 솔루션을 개발해 선보였다.
| |
 |
|
| ▲ ‘인피니플럭스’ 개요 |
기업명과 동명인 ‘인피니플럭스’는 정형·반정형데이터를 실시간으로 처리하기 위한 컬럼 기반 DBMS로, 데이터 발생량이 클수록 데이터의 발생시점과 실제 저장되고 다시 검색되는 시점의 시간적인 간격이 벌어지게 되는 기존 솔루션들과 달리 이러한 간격이 최소화되도록 설계된 점이 특징이다. 이를 위해 실시간 인덱스 구성, 실시간 질의처리, 실시간 데이터 압축, 병렬 디스크 활용 등의 기술을 자체 개발해 적용했다. DBMS로서의 트랜잭션 처리는 배제, DML 가운데 업데이트를 지원하지 않으나 인서트와 셀렉트를 위한 성능이 강화됐다.
이를 통해 싱글노드에서의 데이터 저장 및 분석 속도를 극대화하면서 효율성까지 갖춰, 초당 10만 건 이상의 데이터를 저장하고 검색할 수 있을 뿐만 아니라 4TB 수준 디스크의 경우 100억 건 이상의 데이터를 저장하고 분석할 수 있는 성능을 지녔다. 특히 임베디드 환경에서 데이터를 빠르게 처리하는데 특장점을 지녔으며, 사용성도 중시해 누구나 웹사이트에서 다운로드 받아 테스트해볼 수 있게끔 패키지화가 진행됐다.
‘인피니플럭스’는 최근 시큐아이의 차세대 방화벽 MF2 시리즈에 도입됐으며, 모든 네트워크 패킷 정보의 저장·감시·관리를 위해 ETRI(한국전자통신연구원)에서 개발하고 있는 ‘사이버 블랙박스’ 프로젝트에도 채택됐다. 내년에는 MPP를 지원하는 차기 버전도 선보일 예정이다.
| [인터뷰] “시계열 빅데이터 DBMS로 글로벌 시장 정조준”
| |
 |
|
| ▲ 김성진 인피니플럭스 대표 |
인피니플럭스, 어디에 쓰이나.
비(非) 트랜잭션 형태 데이터가 트랜잭션 기반 데이터의 양을 넘은 상황에서, 고객들은 전통적 데이터 관리보다는 폭증하는 데이터의 저장과 관리에 더 관심을 보이고 있다. 앞으로는 시계열 빅데이터를 생산하는 IoT 혹은 관련 산업 영역에서 비즈니스 기회가 급증할 것으로 보며, 이러한 영역에서 준비된 시계열 전문 DBMS로 자리 잡고자 한다.
‘인피니플럭스’는 데이터의 실시간 응답성이 매우 높고, 그러한 데이터를 반드시 저장해야만 하는 요구가 있는 영역에서 잘 활용될 수 있다. 보안 장비에 탑재돼 초당 수만 건 이상 발생하는 시계열 데이터를 저장하는 곳에 쓰이고 있으며, 임베디드 환경에서 데이터를 초고속 처리할 수 있으므로 자동차, 선박, 비행기, 공장 자동화를 비롯해 병원 등 생체 센서 데이터 등 미션 크리티컬한 부분에서도 두각을 나타낼 것이다.
인피니플럭스의 향후 계획은.
다양한 형태의 실시간 시계열 빅데이터가 많이 발생할 수밖에 없는 메가트렌드에 우리가 서있다고 생각하며, 이 분야에서 세계 최고의 성능을 지닌 솔루션이라면 글로벌 시장에서도 좋은 성과가 있을 것으로 믿는다. 이런 관점에서 자사는 품질을 기반으로 패키지화를 진행하고, 모든 관련 문서와 자료를 영문화하며, 인지도 상승과 사용자 확보를 위한 오픈소스 전략도 고려하는 등 철저하게 글로벌 제품화를 꾀하고 있다. |
실시간 운영 인텔리전스 SW 대표주자 ‘스플렁크’
스플렁크(Splunk)는 실시간 운영 인텔리전스(Operational Intelligence) SW를 개발·공급하는 미국 기업으로, 로그데이터 검색엔진에서 발전해 현재는 실시간 분석 솔루션 시장을 선점하고 있다. 지난 6월 기준으로 포춘지 선정 100대 기업 중 80개를 포함해 글로벌 기업과 정부기관 9,500여 곳을 고객사로 확보하고 있으며, 스플렁크를 통해 매일 400TB가 넘는 데이터를 분석하는 고객도 존재한다. 최근에는 가트너 매직쿼드런트 SIEM(보안정보이벤트관리) 부문에서 3년 연속 리더로 선정된 바 있다.
스플렁크는 세 가지 키워드로 설명할 수 있다. 첫 번째는 엔터프라이즈다. 품질이나 확장성 및 다양한 유스케이스(use case)를 지원한다는 점에서 엔터프라이즈급 플랫폼을 제공한다. 두 번째는 솔루션이다. 전문가들과 외부 개발자 및 파트너들은 고객의 구체적인 유스케이스에 맞는 앱과 애드온(add-on)을 제공, 현재 ‘스플렁크베이스(Splunkbase)’에는 700여 건이 넘는 앱이 올라와 있다. 세 번째는 클라우드다. 모든 솔루션을 하나의 서비스로 제공할 수 있도록 설계해 개발기간을 단축하는 한편, 클라우드 솔루션과 온프레미스(on-premises) 솔루션 및 하이브리드 솔루션도 제공하고 있다.
| |
 |
|
| ▲ ‘스플렁크’ 기술 포트폴리오 |
핵심 플랫폼인 ‘스플렁크 엔터프라이즈’는 웹사이트, 비즈니스 애플리케이션, 소셜미디어 플랫폼, 앱 서버, 하이퍼바이저, 센서, 전통적인 DB, 오픈소스 데이터 저장소 등에서 준실시간으로 데이터를 수집·검색해 분석하고 시각화할 수 있다. ‘서치(search)’라는 고유의 명령 언어를 가졌고, 재인덱싱할 필요 없는 분산 구조로 데이터를 시계열 형태로 저장해 빠른 검색과 높은 확장성을 지원한다. 플랫폼으로서 앱 생태계가 잘 갖춰져 있어 전문적인 용도로도 다양하게 활용할 수 있고, 패키지화가 잘 이뤄져 웹사이트에서 다운로드받아 간편하게 테스트해볼 수도 있다.
이와 함께 스플렁크는 ‘스플렁크 엔터프라이즈’ 플랫폼을 기반으로 다양한 제품들을 제공하고 있다. 하둡용 분석 솔루션 ‘헝크(Hunk)’, 개인 사용자나 소규모 IT환경 대상 ‘스플렁크 라이트’, 클라우드 및 하이브리드 환경을 위한 ‘스플렁크 클라우드’, 모바일 앱의 성능과 문제 및 사용량을 파악할 수 있는 ‘스플렁크 민트(MINT)’ 등이다.
| [인터뷰] “간편하게 빅데이터 분석을 시도해볼 수 있는 플랫폼”
| |
 |
|
| ▲ 김대원 스플렁크코리아 지사장 |
스플렁크, 어디에 쓰이나.
스플렁크는 모든 산업군에 운영 인텔리전스 솔루션을 제공하고 있다. 실시간 분석 솔루션 시장은 스플렁크가 선도적으로 개척한 시장이라 자부한다. 스플렁크의 솔루션은 주로 보안과 IT운영관제 목적으로 쓰이며, 주요 고객은 정부, 온라인 서비스, 고등 교육기관, 금융, 의료, 리테일, IT, 게임 등 다양하다. 장기적으로는 제조 분야에 관심을 갖고 있다. 글로벌에서는 50%의 성장세를 유지하고 있으며, 국내도 이와 비슷한 수준이다.
스플렁크의 향후 계획은.
스플렁크의 목표는 장차 데이터 플랫폼의 표준으로 자리 잡는 것이다. 또한 플랫폼으로서 지속적으로 발전해나가는 생태계를 만들어나가는 것도 주요 목표다. 이는 스플렁크코리아의 목표이기도 하다. IT기술 트렌드를 선도하고 있는 입장에서 고객들과 파트너들에게 이점을 제공할 수 있다고 생각하며, 구호나 말뿐이 아니라 직접 활용해보고 결정할 수 있게끔 하고 있다. 이를 통해 고객의 불편이 해소되고 ROI(투자수익율)를 얻게 될 수 있다면 간편하게 빅데이터 분석을 시작할 수 있도록 지원하고자 한다. |
데이터스트림즈의 신성장동력 ‘테라스트림 바스’
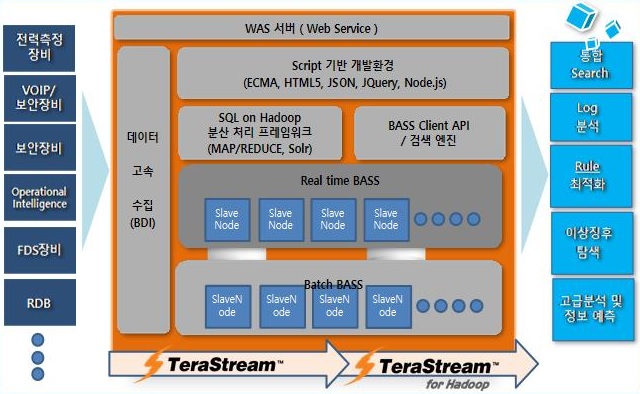
데이터스트림즈는 데이터관리SW 전문기업으로, 자체 개발한 데이터 통합 및 데이터 품질 관리 솔루션을 공급하고 있다. 주력 제품인 ETL 툴 ‘테라스트림(TeraStream)’은 데이터 통합 시장에서 1위를 차지하고 있으며, 지난 2012년 이후부터는 DW 및 BI 분야로 사업을 확장하면서 다양한 데이터 기반 비즈니스를 아우르는 기업으로 변화하고 있다. 지난해에는 다양한 IoT 데이터를 실시간 분석하는 인메모리 기반 실시간 스트리밍 데이터 처리 플랫폼 ‘테라스트림 바스(TeraStream BASS)’를 출시하며 신성장동력 발굴에 나섰다.
‘테라스트림 바스’는 메모리 기반 분산저장 플랫폼으로, 인덱싱과 동시에 저장하는 아키텍처가 기반이 된다. 각종 솔루션 전문 분야를 탑재하기 위한 부분과 OLTP성 FDS 또는 운영 인텔리전스 처리를 지원하며, 웹서버를 탑재해 고급 분석 및 정보 예측 분야를 지원한다. 150바이트(byte) 기준 1개 노드당 초당 200만 건의 저장속도, 60ms(밀리초)의 검색속도, PB급까지 속도가 유지되는 검색 용량을 제공한다.
| |
 |
|
| ▲ 데이터스트림즈 ‘테라스트림바스’ 구조 |
특히 정형은 물론 반정형·비정형까지 다양한 데이터를 메모리에 빠르게 저장해 실시간으로 분석할 수 있게 해주며, 시각화 구현방식의 유연성과 고객사 구축환경에 따른 커스터마이징을 지원한다. 과거 데이터는 메모리에서 HDFS(하둡분산파일시스템)로 내리는데, MR(맵리듀스) 관련 알고리즘을 자체적으로 개선해 이 데이터에 대한 관리성능이 향상된 것도 특징이다. ‘테라스트림’과의 호환성도 좋아 기존 RDB의 데이터도 원활하게 활용할 수 있다.
‘테라스트림 바스’는 실시간 빅데이터 기반 전력 감시 및 분석, 보안장비 로그 분석, 실시간 서버장비 이벤트 로그 분석, 실시간 IDC 센터 관제 및 모니터링, VOIP 이상징후 검색, 각종 센서 데이터 실시간 로그 분석, 빅데이터 기반 실시간 빌딩 에너지 최적화, 실시간 도로위험기상정보 생산 위한 관측, 공장 설비 데이터 실시간 분석, 실시간 통신 서비스 품질 분석, 제조업 공정라인 실시간 데이터 분석, MES 데이터 실시간 연계, 홈 서비스 장애 진단 시스템, IoT 융합 서비스 등에 적용해 활용 가능하다.
| [인터뷰] “더 빠르게, 더 다양하게, 더 편하게”
| |
 |
|
| ▲ 정현규 데이터스트림즈 이사 |
테라스트림 바스, 어디에 쓰이나.
‘테라스트림 바스’는 실시간 빅데이터 분석 및 감시 솔루션을 제공하는 메모리 기반 플랫폼으로, IoT를 겨냥한 실시간 분석 시스템이다. 다양한 데이터를 빠르게 수집해 메모리 분산 저장 장치에 저장하고, 오래된 데이터는 하둡의 HDFS에 분산 저장 처리하는 하이브리드 분석 기능을 제공한다. 감시, 예측, 의사결정, 경고, 모니터링, 관제 등 조회 및 분석 성격의 업무에 주로 사용되며, 공공과 금융 분야 위주로 문의가 오고 있다.
데이터스트림즈의 향후 계획은.
공공기관 및 기업에서 신규 빅데이터 분석 플랫폼 구축과 시범서비스 또는 파일럿(pilot)구축사업, 그리고 기 구축 플랫폼의 고도화와 서비스 확장사업이 공공기관 위주로 많이 진행되고 있다. 데이터스트림즈는 고유의 데이터통합 및 데이터 거버넌스, 메모리 처리기술을 기반으로 하둡 등 오픈소스 기술을 접목해 빅데이터 분석플랫폼 솔루션으로 국내는 물론 해외시장에 집중할 계획이다. 또한 앞으로 반정형·비정형데이터 관리 분야도 선점해나갈 방침이다. |
이디엄의 간편한 제안 ‘로그프레소’
이디엄은 지난 2013년 세 명의 공동창업자가 설립한 스타트업이다. 이들은 설립 이전인 2008년부터 로그데이터 처리 기술을 함께 연구해왔으며, 현재 이디엄은 ‘실시간 역인덱스 생성 및 검색 기술’, ‘이벤트 처리시스템의 이벤트 처리방법’ 등의 특허를 보유하고 있다. 설립과 함께 출시한 ‘로그프레소(LogPresso)’는 ‘로그데이터의 핵심 의미를 에스프레소 커피머신처럼 빠르게 추출한다’는 뜻를 담은 실시간 빅데이터 분석 플랫폼으로, 올해 3.0버전 출시를 앞두고 있다.
5년여의 엔진 개발을 거쳐 출시된 ‘로그프레소’는 시계열 머신데이터에 대한 실시간 풀텍스트/필드 인덱싱 기술을 지원, 1년 이상 운영하더라도 데이터 누적에 의한 성능 저하가 일어나지 않는다. 또한 실시간 데이터 수집, 분석, 저장, 시각화의 전 과정을 하나의 솔루션에서 구현한 점이 특징이다. 일반적으로 스트림 엔진과 쿼리 엔진은 별개 제품이지만, ‘로그프레소’는 이 두 가지가 결합돼 높은 유연성과 성능을 제공한다.
| |
 |
|
| ▲ 이디엄 ‘로그프레소’ 구조 |
아울러 이벤트 연관 분석을 수행할 수 있도록 자체 CEP 엔진이 내장돼 FTP, SFTP, HDFS, JDBC 등 다양한 외부 리소스를 스트림에서 조인할 수 있으며, 별도 개발 없이 모든 ETL 작업이 쿼리로 가능하다. 필드 암호화 및 테이블 단위 암호화까지 자체적으로 지원하며, 이러한 모든 기능이 통합돼 있으므로 데이터와 목적이 분명하다면 당일 분석을 시작할 수 있을 정도로 간편하게 구축할 수 있는 것이 강점이다.
더불어 사용성 측면에서도 드래그앤드롭으로 다양한 위젯을 배치해 대시보드를 구성할 수 있고, 웹 관리화면에서 수집 설정부터 시각화까지 전 과정을 수행할 수 있다. 페더레이션 기반 분산처리를 지원하며, 최소한의 하드웨어 장비로 운영 가능한 비용효율성과 간단한 구성에 따른 관리편의성도 제공한다.
| [인터뷰] “경험에서 우러나온 사용자 중심 솔루션”
| |
 |
|
| ▲ 구동언 이디엄 COO |
로그프레소, 어디에 쓰이나.
‘로그프레소’는 대용량의 정형·비정형데이터를 수집, 검색, 분석, 시각화해 신속한 의사결정을 돕는 솔루션이다. 기존의 RDB로는 쏟아지는 로그를 처리하는데 한계를 느껴 개발하기 시작했고, 2009년부터 2년간 보안 스타트업 엔초비를 할 때도 꾸준히 개발해왔다. 현재 경쟁사 대비 최소 3배 이상 높은 인덱싱 처리 및 검색 성능을 제공하고, 평균적으로 6배 이상 적은 하드웨어 장비를 필요로 한다. 0.5초 이내 실시간 응답요건을 충족해야 하는 FDS(이상거래탐지)를 비롯해 LTE통신로그분석과 보안관제 등에 쓰이고 있다.
이디엄의 계획은.
‘로그프레소’를 현업에서 더 쓰기 편하게 발전시키고자 한다. 데이터 파싱 및 정규화의 어려움을 해결해주고, 스트림에 대한 멀티노드 로드밸런싱이나 페일오버가 가능하도록 개발하려 한다. 사용자 정의 분석 화면 설계, 클릭을 이용한 데이터 분석 지원, 인터랙티브 드릴다운 분석, 사용자 정의 보고서 출력 등도 계획하고 있다. 장기적으로는 클라우드 기반 데이터 처리 플랫폼으로 서비스하는 것을 염두에 두고 있다. 내년부터는 글로벌 시장 공략도 본격적으로 시작할 예정이다. |
솔트룩스의 전략적인 행보 ‘D2’
솔트룩스는 정형·비정형데이터 융합·분석과 인공지능(시맨틱) 기술 기반의 B2B 솔루션 사업 및 클라우드 컴퓨팅 기술을 접목한 B2C 소셜서비스를 제공하고 있다. GS인증 등 다양한 인증과 수상, 80건의 특허 출원 및 31건의 등록 특허 등 다수의 지적재산권을 보유하고 있으며, 배트남 개발센터를 포함해 일본, 중국 지사뿐만 아니라 미국, 유럽 등 전 세계적으로 사업 및 연구개발 파트너를 확보하고 있다.
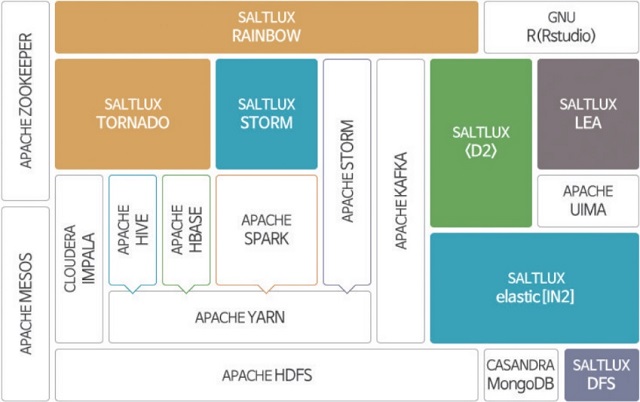
솔트룩스는 10년 전부터 대규모 비정형데이터 또는 통신데이터, 유럽과의 R&D 사업, 센서 및 IoT 관련 공동연구 사업을 추진해오면서 시장 변화를 감지해 실시간 데이터 분석 플랫폼 ‘D2’를 비롯한 모든 아키텍처와 기술을 발전시켜왔고, 시맨틱 검색과 텍스트마이닝을 넘어 빅데이터 기반 기계학습과 온톨로지 기반 추론을 융합한 스마트데이터 제품과 빅데이터 검색·분석 솔루션을 선보이게 됐다고 밝혔다.
| |
 |
|
| ▲ 솔트룩스 ‘빅O’ 구조 |
‘D2’는 ▲단일 서버에서 초당 5만 건 이상의 실시간 스트림 빅데이터 처리 ▲정형·비정형 빅데이터의 융합 분석 ▲시계열 패턴 감지를 포함한 실시간 패턴 감지와 CEP ▲집합연산, 고급 통계 분석과 개체명 인식 및 감성분석 등 강력한 실시간 분석 질의어 ▲예측과 자동 알림 기능 ▲실시간 시각화와 R 연동 등을 주요 특징으로 내세우고 있다. 텍스트, 트위터, 기업 내부 문서, 이메일 등 비정형데이터를 실시간 분석할 수 있고, 고객의 사용목적에 맞게 커스터마이징 가능하고 비용효율적으로 제공되는 것이 장점이다.
솔트룩스는 오픈소스와 결합된 ‘빅O(BigO)’ 플랫폼도 선보이고 있다. 얀(YARN)을 포함한 하둡뿐 아니라 ‘아파치 스파크’, 실시간 스트림 데이터 처리를 위한 ‘스톰(STORM)’과 UIMA 프레임워크를 ‘IN2’, ‘D2’, 솔트룩스 ‘스톰’ 등과 통합 구성함으로써 대용량, 실시간 데이터의 수집, 저장, 검색과 병렬/분산 분석 및 시각화 등의 기능을 하나의 플랫폼에 구현했다는 설명이다.
| [인터뷰] “이제는 스마트데이터 시대”
| |
 |
|
| ▲ 이경일 솔트룩스 대표 |
D2, 어디에 쓰이나.
솔트룩스는 빅데이터와 인공지능 기술을 결합한 특징을 갖고 있고, 비정형 빅데이터 분석 및 시맨틱 기술을 기반으로 국내외 다양한 빅데이터 및 검색 프로젝트의 80% 이상을 구축해왔다. 실시간 분석 시장도 궁극적으로 머신데이터뿐 아니라 휴먼데이터와의 융합 분석으로 발전하리라 보고 있으며, ‘D2’에도 이를 위한 기술이 반영됐다. 주로 보안 및 안보 분야에서 쓰이고 있으며, 스마트팩토리와 IoT 관련 분야에도 빠르게 적용되고 있다.
솔트룩스의 향후 계획은.
그간 수집과 저장 관련 이슈에 다소 치우쳐있던 빅데이터 시장이 이제 빠르게 변화하고 있다. 향후 2~3년 내로 빅데이터에 인공지능을 적용한 스마트데이터가 실질적인 가치를 만들며 주목받을 것이다. 자사는 이를 위해 기계학습과 딥러닝의 결합을 통한 예측 분석 기술 개발에 집중할 계획이다. 또한 DaaS(Data as a Service) 서비스 사업을 지속 확장해나갈 예정으로, 분석 클라우드 서비스 ‘O2’의 확장 버전인 ‘데이터 믹시(DATA MIXI)’ 서비스도 준비 중이다. 2020년에는 세계 10대 지식서비스 기업이 되는 것이 목표다. |
|
|
reference : http://www.itdaily.kr/news/articleView.html?idxno=68224
IT News 2014. 10. 28. 11:26
RDBMS와 NoSQL Solution을 통틀어 주요 특징의 장단점을 기술하고, 4개의 Category 영역에 비율을 명시한 자료.
국내 DB업체로는 Altibase와 TMAXData(이전 Tibero)가 눈에 띄네요.
16 October 2014 ID:G00261660
Analyst(s): Donald Feinberg, Merv Adrian, Nick Heudecker
VIEW SUMMARY
The operational DBMS market continues to grow, with innovative products and features being delivered by both new and traditional vendors. Information management leaders will be particularly interested by the changes in the Leaders quadrant. 
Market Definition/Description
The operational database management system (DBMS; see Note 1) market is defined by relational and nonrelational database management products that are suitable for a broad range of enterprise-level transactional applications. These include purchased business applications such as enterprise resource planning (ERP), customer relationship management and customized transactional systems built by an organization's development team. In addition, we include DBMS products that also support interaction data and observation data (see Note 2) as new transaction types. These products are also used both for purchased business applications, such as ERP, catalog management and security event management, and for customized systems.
Additionally, operational DBMSs should provide interfaces to independent programs and tools that permit, and govern the performance of, a variety of concurrent workload types. There is no presupposition that these DBMSs must support the relational model or the full set of data types in use today. Further, there is no requirement that the DBMS be a closed-source product; commercially supported open-source DBMS products are included in this market.
Operational DBMSs must include functionality to support backup and recovery, and have some form of transaction durability — although the atomicity, consistency, isolation and durability (ACID) model is not a requirement. For open-source DBMSs, maintenance and support must be available from a vendor that owns, or has substantial control over, the source code, and must be offered with a full General Public License (GPL) or an alternative.
For this Magic Quadrant, we define operational DBMSs as systems that support multiple structures and data types, such as XML, text, JavaScript Object Notation (JSON), audio, image and video content. They must include mechanisms to isolate workload resources and control various parameters of end-user access within managed instances of data (see Note 3). Emerging technologies, such as cloud-only DBMSs, are not included; nor are highly specialized engines such as graph-only or object databases, which may perform some transactions for small subsets of operational use cases. Products that "add a layer" to and require or embed a complete or near-complete implementation of another commercially marketed product, such as Oracle MySQL, are not included. Finally, "streaming" engines, whose use cases are dominated by immediate event processing, and which are rarely, if ever, used for subsequent management of the data involved, are also excluded.
For the purposes of this analysis, we treat all of a vendor's products as a set. If a vendor markets more than one DBMS product that can be used as an operational DBMS, we describe them in the section specific to that vendor, but we evaluate all of that vendor's products together as a single entity. Strengths and Cautions relating to a specific offering or offerings are noted in the individual vendor sections. It may be important for organizations to evaluate separate offerings as the range of choices broadens, and as purchasers more frequently pursue best-of-breed strategies.
Operational DBMSs may support multiple delivery models, such as stand-alone DBMS software, certified configurations, cloud (public and private) images or versions, and database appliances (see Note 4). These are discussed and evaluated together in the analysis of each vendor.
Magic Quadrant
Figure 1. Magic Quadrant for Operational Database Management Systems
Source: Gartner (October 2014)
Vendor Strengths and Cautions
Actian
Headquartered in Redwood City, California, U.S., Actian offers relational DBMS (RDBMS; Ingres) and embedded (PSQL) engines, both suitable for operational use. Following a recent repositioning, Actian focuses primarily on analytical use cases.
Actian did not respond to Gartner's requests for supplementary information or to review early drafts of this section. Our analysis is therefore based on other credible sources, including publicly available information, previous briefings with Actian, and interactions with users of Gartner's client inquiry service.
Strengths
- Large customer base: Actian claimed to have over 210,000 customers at mid-2013. Broad geographic and industry coverage for Ingres, and a loyal following for PSQL, remain in place in 2014.
- Rich portfolio: Actian's offerings provide modern features, including multiversion concurrency control (MVCC), object and geospatial support, and column-level encryption.
- Embeddable offering: Actian's PSQL gives it a means of entering the small-footprint, minimal-administration market that is so important to mobile and Internet of Things applications.
Cautions
- Complex portfolio, focused elsewhere: Actian's recent positioning efforts are aimed at analytics, not operational use cases.
- Deployment challenges: Actian received the lowest scores from customers surveyed in 2013 for ease of use, and very low scores for ease of implementation. Our interactions with users of Gartner's client inquiry service in 2014 paint the same picture.
- Market focus: Gartner's interactions with clients continue to indicate a lack of momentum from Actian in relation to its operational DBMS and support of its Ingres DBMS.
Aerospike
Headquartered in Mountain View, California, U.S., and founded in 2009, Aerospike markets a hybrid in-memory/flash NoSQL DBMS — a real-time data platform — for the operational transaction market. It is available both as an open-source community version and an Enterprise Edition.
Strengths
- Operational DBMS functionality: Aerospike's offering makes hybrid use of DRAM and flash as addressable memory and not as file system support. Synchronous copies and support for multiple data centers add high availability (HA) and disaster recovery (DR) capabilities. Aerospike's hybrid DBMS structure supports JSON and NoSQL key-value data.
- Marketing and hardware ecosystem: Aerospike has strong partnerships with hardware component vendors for DRAM and flash memory. Its marketing focuses on the market segment that requires high transaction rates with near-100% availability.
- Performance: Aerospike's reference customers supported its claims of high performance by awarding it the highest scores for performance of any vendor in this Magic Quadrant. They also gave it the highest score for ease of doing business.
Cautions
- Lack of full functionality: Aerospike is strong in HA functionality but lacking in some basic SQL and NoSQL functions, although it has added some SQL functionality.
- Competitive positioning: With an increasing number of vendors supporting in-memory DBMSs, Aerospike will need to differentiate itself more clearly. Many vendors have much larger marketing programs — a disadvantage for Aerospike.
- HA/DR and ease of programming: Aerospike's reference customers identified difficulties in programming and the management of HA/DR as weaknesses of its product, probably due to the complexities of DR.
Altibase
Headquartered in Seoul, South Korea and Palo Alto, California, U.S., Altibase offers Altibase HDB, an SQL operational DBMS capable of using in-memory, traditional disk or hybrid storage. Altibase XDB is an in-memory-only DBMS.
Strengths
- Performance and support: Reference customers gave Altibase high marks for the overall performance of its operational DBMS, and for its support, professional services and ease of use.
- Broad use case applicability: In addition to applying its technology to unique billing scenarios in the telecommunications sector and real-time flaw detection in manufacturing scenarios, customers use Altibase HDB for analytics and storage of textual and rich-media content.
- Product maturity: Over 85% of Altibase's reference customers reported no problems with its product.
Cautions
- Limited global penetration: Although successful in Asian markets, Altibase has yet to establish much brand awareness or penetration elsewhere. The company has recently established several partnerships with global organizations.
- Shortage of large reference customers: Reference customers themselves stated that Altibase's limited number of globally recognized reference customers made adoption more difficult.
- Narrow product focus: Altibase does not support alternative consistency models or support multimodel capabilities, such as documents and graphs.
Basho Technologies
Newly headquartered in Seattle, Washington, U.S., Basho Technologies offers Riak, a distributed, masterless key-value store. It is available as a free, open-source, Apache-licensed download, as an Enterprise Edition, and as Riak CS, a multitenant cloud object store. Basho offers an Amazon Simple Storage Service (S3) API and a cloud service.
Strengths
- Resilience: Riak provides multi-data-center distribution and replication with automated balancing; it does not fail upon server failure or network partition.
- Rich features: Riak offers secondary indexes, MapReduce, support for JSON, tunable consistency, multiple programming languages, Apache Solr support and pluggable storage engines.
- Growing paid customer base: Basho's customers include one-third of the Fortune 500 companies in North America and EMEA. It also has a strong community, which contributes to the product.
Cautions
- Single architecture focus: Riak's key-value-only architecture limits its broader adoption and therefore restricts Basho to the Niche Players quadrant in the operational DBMS market.
- Growing competition: Major vendors will continue to add key-value functionality (such as Microsoft Azure Tables and Oracle NoSQL, both already available), which will create additional competition for key-value use cases.
- Recent changes to management team and reorganization of company: These suggest that prospective customers should conduct a careful assessment before making major commitments to Basho, even though its funding is strong and likely to grow.
Cloudera
Headquartered in Palo Alto, California, U.S., Cloudera offers Cloudera Enterprise, a commercial version of Apache Hadoop for which Apache HBase provides the operational DBMS capabilities. Cloudera Enterprise is available on-premises, as an appliance and through various cloud providers.
Strengths
- Support for emerging use cases: 80% of Cloudera's reference customers use Cloudera Enterprise for storing and processing machine-generated data, such as clickstreams and sensor data. Using this observational data in transactions is now possible with HBase.
- Scalability: Cloudera's reference customers repeatedly mentioned Cloudera Enterprise's ability to scale to accommodate massive data volumes.
- Stability and ecosystem: Cloudera has raised over $1.2 billion in venture funding and has developed a large partner ecosystem that encompasses every relevant segment of the enterprise software market.
Cautions
- Challenging implementation and use: Reference customers scored Cloudera lowest of all the vendors in this Magic Quadrant for ease of implementation. It also scored poorly for ease of operation and programming, and support and documentation.
- Lack of differentiation: Cloudera's operational DBMS, Apache HBase, is also offered by its competitors.
- Focus: The operational DBMS is only one component of Cloudera Enterprise. It may have to compete for development and support resources with the rest of the product suite.
Clustrix
Headquartered in San Francisco, California, U.S., Clustrix offers a low-administration, shared-nothing, distributed RDBMS, ClustrixDB, with automatic sharding and replication. It is available as on-premises software and in the cloud. Clustrix also provides a managed database as a service.
Strengths
- Performance: Clustrix provides extreme scale-out clustering for performance and availability. Parallel SQL query execution across a cluster supports hybrid transaction/analytical processing (HTAP) use cases.
- Simplicity: The Clustrix database is designed to be largely self-managed, to reduce operational complexity and total cost of ownership (TCO). Integration is simplified by the implementation of the MySQL wire protocol.
- E-commerce focus: Clustrix recently announced a new focus on applying its scale-out DBMS to e-commerce applications that face scaling challenges.
Cautions
- Lack of multimodel capabilities: ClustrixDB offers no support for data types beyond traditional relational ones. More than half its reference customers have deployed another operational DBMS to support nonrelational use cases.
- Value challenges: Clustrix received low scores from its reference customers for overall value for money. However, all reference customers were using the Clustrix appliance, not a software-only product.
- Poor early performance: Half the Magic Quadrant survey respondents who did not select ClustrixDB stated that this was because its product performed poorly during a proof of concept (POC) exercise.
Couchbase
Headquartered in Mountain View, California, U.S., Couchbase offers an open-source, distributed multimodel (document and key value) NoSQL DBMS, Couchbase Server. It is offered in Community, Enterprise and Lite Editions for on-premises, mobile or cloud deployment.
Strengths
- Rich feature set: Couchbase's March 2014 release, Couchbase Server 2.5.1, offers in-memory object caching, automatic partitioning, limited ACID transaction support, "eventual persistence" (optional nonblocking writes to a caching layer), cross-data-center replication, a synchronized, lightweight, embedded JSON DBMS, and MapReduce support. Couchbase also has a strong technology road map.
- Large customer base and revenue growth: Gartner estimates that Couchbase has over 450 customers in several industries. It also claims to have achieved 400% revenue growth in the past year as its deal sizes have increased.
- Financial and partner strength: Couchbase added a $60 million "E" venture funding round in June 2014, which is helping to fund growth in its international presence. Couchbase has established relationships with several hardware partners and leading system integrators.
Cautions
- Quality: The number of responses from Couchbase's reference customers that reported bugs or unreliable software was significantly above the average for this Magic Quadrant.
- Missing functionality: Of the surveyed Couchbase customers, 48% reported some absent or weak functionality. Some of these functions are on the road map, but not implemented yet.
- Competition: Growing pressure from megavendors and MongoDB, especially in document-oriented use cases, is likely as interest in these use cases grows.
DataStax
Headquartered in Santa Clara, California, U.S., DataStax provides DataStax Enterprise, a commercial version of the open-source Apache Cassandra database. The product is downloadable for on-premises operation, as well as through multiple cloud providers.
Strengths
- Customer satisfaction: Reference customers scored DataStax above average for most metrics, and awarded very high scores for overall DBMS performance and their experience of doing business with this vendor.
- Expanding functionality: DataStax has added in-memory transactions, search capabilities, and support for analytics through Apache Spark and Apache Hadoop. Reference customers identified administration and development tools as positives.
- Vibrant community: DataStax has helped develop a robust open-source community around Apache Cassandra through developer and enterprise conferences.
Cautions
- Weak brand traction: Inquiries from Gartner clients mention DataStax only one-third as often as the open-source project Apache Cassandra. The market has yet to consistently associate DataStax with Apache Cassandra.
- Challenging starts: 53% of the respondents who evaluated DataStax did not select it due to poor performance during POC testing. This may indicate a poor fit between the characteristics of DataStax Enterprise and the piloted use cases.
- Quality between versions: Reference customers identified regression bugs when upgrading to new versions. DataStax must continue to invest in improving its quality.
EnterpriseDB
Headquartered in Boston, Massachusetts, U.S., EnterpriseDB supports and markets the PostgreSQL open-source DBMS, which it packages as an open-source community edition and as Postgres Plus Advanced Server, including the Oracle Compatibility Feature.
Strengths
- Community leadership: EnterpriseDB is the primary contributor to the PostgreSQL community. It is responsible for many of the new features of PostgreSQL by contributing to JSON, materialized views and partitioning.
- Functionality: Gartner clients report that the functionality of EnterpriseDB's Postgres Plus Oracle Compatibility Feature is now more than sufficient to run both mission-critical and non-mission-critical applications. Recently, Infor, a major application platform independent software vendor (ISV), added EnterpriseDB as a DBMS platform choice.
- Stability and compatibility: Reference customers commend the compatibility with Oracle, the stability of the DBMS and the product support.
Cautions
- Open-source dilemma: EnterpriseDB must conform to community-led release cycles for its community editions as they go through the open-source process. This can slow the process of enhancing the base open-source product, but not the enterprise edition.
- Market exposure: EnterpriseDB lacks breadth in its sales and marketing operations, which restricts its ability to communicate its message to potential enterprise customers. According to our survey, those that did not choose EnterpriseDB would have been more likely to choose it if they had been more familiar with it.
- Support and documentation: Reference customers reported a lack of local-language support and weak documentation.
FairCom
FairCom, which was founded in 1979, is headquartered in Columbia, Missouri, U.S. and privately owned. FairCom c-treeACE (Advanced Core Engine), one of the oldest NoSQL DBMSs, is a fully ACID, key-value store with both NoSQL (Indexed Sequential Access Method [ISAM]) interfaces and SQL, and supports transactions with an embedded or stand-alone engine.
Strengths
- Strong technology: c-treeACE is a very strong ACID key-value NoSQL DBMS with SQL capabilities and a long history of stability and innovation. Cross-platform support (Unix/Linux/OS X), scalability and strong HA stand out among its capabilities.
- Customer base: FairCom has a large customer base, encompassing both stand-alone and embedded implementations. The OEM (embedded) base is itself large and produces sustainable revenue that enables investment in research and development (approximately 25% of revenue).
- Satisfied customers: FairCom received some of the highest overall scores in our survey, with high marks for customer support, professional services, performance, ease of doing business, ease of operations and HA. Furthermore, over 75% of its reference customers reported no problems with it.
Cautions
- Marketing presence: FairCom lacks presence in the general DBMS market as it has a relatively small marketing budget. Growth largely comes from within its existing customer base.
- Small, largely unknown vendor: FairCom needs greater brand awareness to compete effectively with other operational DBMS vendors, especially the better known NoSQL vendors.
- Pricing: Reference customers identified FairCom's pricing model as an issue. We believe this is because other NoSQL vendors offer an open-source pricing model.
IBM
Headquartered in Armonk, New York, U.S., IBM offers DB2 for z/OS, Linux, Unix, Microsoft Windows and Informix. Depending on the DBMS, IBM offers multiple deployment models, from hardware bundling and appliances to deployment in IBM's SmartCloud or third-party clouds.
Strengths
- Performance and features: Survey participants rated IBM highly (among the top three vendors) for HA/DR and overall performance. In-memory DB2 with Blu Acceleration reflects IBM's early vision for in-memory DBMSs. NoSQL support includes a MongoDB-compatible JSON API for document-style, cloud delivery via its Cloudant acquisition and via Bluemix, and Resource Description Framework (RDF) for graph models.
- Hardware integration: DB2 for z/OS dynamically routes analytics to the IBM DB2 Analytics Accelerator (IDAA), creating an efficient HTAP architecture in a single environment and reducing mainframe MIPS to cut operating charges. Other IBM products, such as IBM PureData System for Transactions, use integrated hardware and software.
- Global presence: IBM provides support, implementation and services in multiple vertical markets. It has one of the IT industry's largest networks of software, hardware and service partners.
Cautions
- Sales execution: Like other megavendors, IBM is opaque in its reporting of revenue and customer numbers, but Gartner's RDBMS market share figures indicate that IBM declined in 2013, losing second place in the market to Microsoft.
- Complexity and pricing: For the second year in a row, survey participants scored IBM low for pricing model suitability. Value for money was considered average. IBM is, however, expanding its aggressive pricing, bundling and simplification efforts.
- Software quality: Surveyed IBM customers rated it worst of all the vendors in this Magic Quadrant for "software with bugs or unreliable software," and below average for ease of implementation and ease of operation.
InterSystems
Headquartered in Cambridge, Massachusetts, U.S., InterSystems was founded in 1978. It markets Caché, which was originally an object-oriented DBMS but is now a hybrid NoSQL/SQL transaction engine. Caché has a strong position in the healthcare sector.
Strengths
- Strong functionality: Caché supports a wide variety of data types with object, NoSQL and SQL models, and has strong replication capabilities for HA/DR (as evidenced by strong scores from its reference customers). Database management is automated, so it requires fewer staff resources.
- Focused execution: After establishing a solid product and a large ISV ecosystem that is embraced by the healthcare industry, InterSystems is addressing other markets and achieving early success. Strong execution in the healthcare sector is one reason why InterSystems has moved into the Leaders quadrant this year.
- Performance: InterSystems received some of the highest scores from reference customers for the overall performance of Caché and for their experience of doing business with the company. This confirms the impression Gartner gets from other interactions with its customers.
Cautions
- Market perception: Although InterSystems has branched out from the healthcare sector, it is still generally perceived as being a healthcare-only provider. It must pursue a stronger market vision to move into the broader operational DBMS market.
- Marketing: InterSystems is a midsize DBMS vendor with potential for continued growth, especially as 60% of its reference customers plan to purchase more from it. Investment in sales and marketing is necessary if InterSystems is to challenge the broader market leaders.
- Pricing: InterSystems received relatively low scores from reference customers for the suitability of its pricing model.
MapR
Headquartered in San Jose, California, MapR provides the MapR Distribution, including Apache Hadoop. The M7 Enterprise Database Edition includes MapR-DB, an operational DBMS compatible with Apache HBase. It is available on-premises and through various cloud providers.
Strengths
- Reliability and performance: Reference customers gave MapR high scores for its HA/DR capabilities and cluster stability. Several commended the performance of MapR's operational DBMS.
- Support for emerging use cases: 90% of MapR's reference customers use M7 to capture and analyze machine-generated data, such as log files, clickstreams and connected device data.
- Differentiation and focus: MapR differentiates itself from similar vendors through its replacement of the Hadoop Distributed File System (HDFS) with the MapR Data Platform, which exposes Network File System access.
Cautions
- Availability of skills: 60% of the survey respondents did not select MapR owing to concerns about the availability of relevant skills within their organization. Additionally, MapR's scores for ease of programming were well below average.
- After-sale support: Reference customers gave MapR lower scores for its support and documentation and for its professional services.
- Complexity: Several reference customers remarked on the complexity inherent in deploying MapR's product and the overall immaturity of its ecosystem.
MariaDB
MariaDB (formerly SkySQL) is headquartered in Espoo, Finland. It markets two products: MariaDB 10, an open-source, in-memory-capable, multimodel RDBMS based on, and fully compatible with, Oracle MySQL; and MariaDB Enterprise, a commercially supported bundle with enterprise-targeted add-on components. Both products are available for Red Hat Enterprise Linux, CentOS Linux, Ubuntu, Debian (which includes MariaDB in its distributions) and Microsoft Windows. The company is headed by the creators of MySQL.
Strengths
- Rich functionality: MariaDB offers multiple storage engines, tunable persistence, ACID support with the InnoDB/XtraDB engine, graph storage with Open Query Graph (OQGraph), and support for Apache Cassandra and JSON.
- Value: In our survey of reference customers, MariaDB received one of the three highest scores for value for money, as it did for suitability of pricing method. It also received one of the highest scores for "no problems encountered."
- Strong community and partner network: MariaDB is at the heart of a vibrant MySQL user community and ecosystem. It partners with Linux distribution vendors, IBM, Fusion-io, and organizations offering products for special-purpose storage engines, management, backup and HA, as well as service providers.
Cautions
- Increased competition: MariaDB is increasingly visible and will face more competition, especially as Oracle's consent decree with the EU regarding MySQL expires in 20151 and Oracle becomes more aggressive.
- Scale: MariaDB's reference customers mostly quantified the size of their largest databases as being a few hundred gigabytes at most. To compete at the high end against increasing competition, MariaDB will require more terabyte-size reference customers.
- Fragmented offerings: Several customers remarked on the number of separate pieces in MariaDB's software stack; one noted there are "too many independent tools for managing databases."
MarkLogic
Headquartered in San Carlos, California, U.S., MarkLogic offers a document store DBMS in commercial Essential Enterprise, Global Enterprise and Mobile editions, and free, fully-featured developer versions. Its software can be deployed in VMware and Amazon Web Services environments, and, in collaboration with SGI, as the DataRaptor appliance. In 2014, MarkLogic enters the Leaders quadrant for the first time.
Strengths
- Features: MarkLogic's mature enterprise features are extended with tiered storage, HDFS support, backup to Amazon S3, JSON, mobile replication, full text search, geospatial capabilities, Sparql language support, Resource Description Framework (RDF) import support and a converter for MongoDB. Its road map is rich and ambitious.
- Solid customer base and partner network: We estimate that, following recent sizable wins in the financial services sector, MarkLogic now has over 300 commercial customers. It also has a sizable partner ecosystem, which should add momentum to its recent solid growth.
- Customer relationship: Reference customers gave MarkLogic high marks for their experience of doing business with it.
Cautions
- Pricing challenges: Surveyed customers ranked MarkLogic low in terms of value for money and suitability of pricing model. However, MarkLogic altered its pricing structure in 2013 and lowered its prices, and Gartner expects to see this reflected in future surveys.
- Difficult to use: Of the vendors evaluated in this Magic Quadrant, MarkLogic received the lowest overall score from survey respondents for ease of programming. For continued growth, delivery of planned product enhancements and programming language support is essential.
- Geographic concentration on North America: Well over 80% of MarkLogic's customers are in North America. Its overseas expansion efforts must succeed if it is to compete with global providers.
McObject
Headquartered in Issaquah, Washington, U.S., McObject offers eXtremeDB version 5.0, a small-footprint relational in-memory DBMS with extended array and vector support. Since 2001, millions of copies of eXtremeDB have been deployed worldwide in embedded and real-time applications.
Strengths
- Deployment and configuration choices: Typically embedded, eXtremeDB supports Microsoft Windows, Linux, real-time OSs and the Java Native Interface. Clustered configurations are available.
- Functionality: eXtremeDB provides full ACID and tunable persistence, multiversion concurrency control, 64-bit support and hybrid storage for scalability.
- Partnerships: McObject has partnerships with EMC, Fusion-io, HP, IBM and others. Numerous distributors market its product, and it has customers worldwide.
Cautions
- Marketing: eXtremeDB's multiple engines and horizontal and vertical scalability remain little-known in the market.
- Limited targets: eXtremeDB is still seen as being marketed primarily for embedded applications, although this is changing.
- Customer satisfaction: Surveyed customers gave McObject low scores for HA/DR, ease of implementation and ease of operation. These are not all new issues. Given the wide distribution of eXtremeDB version 5.0, they reflect a failure to address continuing challenges.
Microsoft
Headquartered in Redmond, Washington, U.S., Microsoft markets its SQL Server DBMS for the operational DBMS market, as well as Microsoft Azure SQL Database (a database platform as a service) and Microsoft Azure Tables. Microsoft now has in-memory row-store technology for transactions in SQL Server 2014.
Strengths
- Market vision: Microsoft's market-leading vision consists of in-memory computing (SQL Server 2014 now has full transaction in-memory support), NoSQL (with a new document-store DBMS), cloud offerings (both cloud-only and hybrid cloud), use of analytics in transactions (HTAP) and support of mobility. Its vision for in-memory computing and putting the "cloud first" is ahead of its competitors.
- Strong execution: Microsoft SQL Server is an enterprisewide, mission-critical DBMS capable of competing with products from the other large DBMS vendors. Gartner's 2013 market share data shows Microsoft taking second place from IBM in terms of total DBMS revenue.
- Performance and support: Reference customers were very positive, with the performance of SQL Server, documentation, support, ease of installation and operation all rated highly. Only 7% reported problems with the DBMS overall.
Cautions
- Lack of an appliance: Microsoft still lacks an appliance for transactions (one comparable to its SQL Server Parallel Data Warehouse appliance), whereas its major competitors (IBM, Oracle and SAP) all offer one.
- Market image: Although SQL Server is an enterprise-class DBMS, Microsoft continues to struggle to dispel a perception of weakness in this area. Inquiries from Gartner clients demonstrate a continuing perception that SQL Server is not used for mission-critical enterprisewide applications — a view that inhibits wider use of SQL Server as a primary, enterprise-class DBMS.
- HA/DR and pricing issues: Reference customers again found the pricing model for SQL Server unacceptable (they gave it the lowest overall rating of any vendor in this Magic Quadrant) and blamed the price changes that came with SQL Server 2012. Microsoft also received one of the lowest overall scores for ease of implementing HA/DR.
MongoDB
Headquartered in New York City, New York and Palo Alto, California, U.S., MongoDB offers an open-source, document-style DBMS, as well as MongoDB Enterprise, a commercial offering available in various service tiers. MongoDB Enterprise is available through several cloud providers, as well as on-premises.
Strengths
- Customer satisfaction: MongoDB received high scores for every measurement of customer satisfaction in the reference customer survey.
- Improving enterprise capabilities: Recently announced partnerships with analytics and data integration vendors enable MongoDB to tell a well-rounded information management story.
- Operational and management support: Continued investment in the MongoDB Management Service simplifies the running of a large cluster in terms of monitoring, backup and recovery, and provisioning.
Cautions
- Increasingly competitive landscape: Over the past year, several vendors have introduced features that compete with MongoDB's core value proposition. MongoDB will face more pressure to differentiate its offerings against entrenched competitors.
- Growing pains: Although many reference customers reported that MongoDB is easy to get started with, several reported challenges architecting MongoDB for large-scale deployments.
- Trendiness with developers: MongoDB's popularity among developers means it is often selected before application requirements are understood. This can result in a poor fit of DBMS capabilities to the application.
Neo Technology
Neo Technology is headquartered in San Mateo, California, U.S. Neo4j is a native graph-style NoSQL DBMS capable of handling transactions with ACID support and clustering for scalability and HA. Neo became an incorporated company in 2011, but began developing its product much earlier, in 2000. Neo4j, which was first used in a production environment in 2003, is offered as both an open-source version and an Enterprise Edition.
Strengths
- Native graph DBMS: Neo4j is a native graph-style DBMS (as opposed to an existing DBMS to which graph capabilities have been added). It is engineered for performance with transactional ACID capabilities in a single instance and offers tunable consistency across clusters for scalability.
- Growth: Since its founding, Neo has seen strong growth from both its open-source version and Enterprise Edition.
- Performance and ease of use: Reference customers identified performance, ease of operation and implementation, and ease of doing business as strengths of Neo.
Cautions
- Graph model: The graph DBMS model is difficult to understand, which lengthens the learning curve. This problem is exacerbated by growing hype from other vendors about the introduction of a graph model on a nongraph DBMS model.
- Small vendor: Although the Neo4j product is over 10 years old and has grown consistently, Neo remains a small vendor that faces all the issues of risk and stability associated with small vendors.
- Pricing model and HA/DR: Reference customers identified Neo's pricing model as an issue. They also expressed dissatisfaction with the product's HA/DR capabilities.
NuoDB
Headquartered in Cambridge, Massachusetts, U.S., NuoDB provides an operational DBMS designed to scale horizontally and elastically. In addition to being available in on-premises and developer editions, NuoDB's product is available on Amazon Web Services.
Strengths
- Delivery and support: NuoDB received top scores for its support and documentation, professional services and ease of programming. We believe this is enabling it to win contracts to replace other vendors in several locations.
- Rapid deployment: On average, reference customers estimated it took less than five months to deploy NuoDB's product in production environments.
- Support for emerging use cases: 80% of NuoDB's reference customers use it for capturing and analyzing machine-generated data, such as clickstreams, log files and connected device data.
Cautions
- Inconsistent experience: Although NuoDB received several top scores for service delivery, documentation and support, reference customers that weren't full of praise were highly critical. As a new vendor, NuoDB is still perfecting its service and support.
- Slow momentum: NuoDB has not established a footprint in the developer community, which commonly provides informal support and initiates tool development. Gartner clients have yet to show interest in NuoDB during calls to our inquiry service.
- Nascent partner ecosystem: NuoDB's partner program is still developing and has yet to attract the necessary numbers to supplement the company's sales and implementation efforts.
Oracle
Headquartered in Redwood Shores, California, U.S., Oracle markets a complete set of DBMS products for operational systems. These include Oracle Database, Oracle TimesTen, Oracle Berkeley DB, Oracle NoSQL Database and MySQL. In addition to software, several of Oracle's DBMSs are available in engineered systems (appliances).
Strengths
- Broad range of offerings: Oracle has the broadest product portfolio in the market, covering different DBMSs for multiple purposes (RDBMS, NoSQL, streaming data and mobile). Also, it offers delivery in the cloud, on appliances and as stand-alone software. According to Gartner's 2013 market share numbers, Oracle remains in first place for total DBMS revenue market share.
- Functionality: Oracle offers extensive functionality, with many new features (such as the JSON data type and Temporal, which replaces Total Recall) and options such as the Oracle Database In-Memory and Oracle Multitenant options, the latter moving multitenancy to the DBMS layer and reducing support and maintenance. Oracle is also pioneering DBMS functionality on silicon, with new SPARC M7 and T7 chips scheduled for delivery in 2015.
- Solid performance and availability: Reference customers again identified Oracle's DBMS performance and availability as primary reasons for implementation.
Cautions
- Public perception of vision: Oracle's marketing continues to downplay its responses to market trends (such as in-memory functionality) until it announces products. Oracle customers who use Gartner's client inquiry service continue to show confusion and disillusionment in this regard, as they have to make assumptions about Oracle's road maps and vision.
- "Push back" on appliances: Users of Gartner's client inquiry service show a reluctance to purchase products (such as engineered systems) due to perceived "lock in" to Oracle's proprietary systems — some functions, for example, are available only on Oracle hardware and appliances, such as those in Exadata Storage Server software.
- Low cost/value and bugs: Reference customers consider Oracle's products to be expensive and therefore that they have the lowest value proposition. Oracle also received one of the highest scores for bugs reported. Finally, in recent Gartner surveys,2 Oracle received the lowest score for ease of doing business.
Pivotal
Pivotal, a spinoff from EMC, is headquartered in San Francisco, California, U.S. It released Pivotal GemFire XD in April 2014, combining GemFire, its distributed in-memory data grid, and SQLFire, its distributed, memory-optimized SQL database, with Pivotal HD, its Hadoop distribution incorporating Hawq (based on the Greenplum massively parallel processing [MPP] column-store DBMS). It is available with Pivotal CF for cloud-based deployment.
Strengths
- Rich functionality: By combining an in-memory transactional engine with Pivotal HD's Hawq analytic SQL engine, Pivotal enables large HTAP-style combinations of real-time transaction and event processing for closed-loop systems. It offers HA, active-active deployment and rolling upgrade support.
- Flexible usages: GemFire provides native object-oriented and REST interfaces; Hawq provides SQL analytics. GemFire XD supports structured data, geospatial data, objects, JSON and key-value pairs.
- Strong global organization: Pivotal has the resources and installed base of EMC as key assets. They include manufacturing, research, and presale and postsale support worldwide.
Cautions
- Maturity: Integrating multiple products is a complex process, and GemFireXD has been on the market for only a few months. Pivotal received the lowest survey scores for support and documentation, and below-average scores for ease of implementation and ease of operation — though this is not unusual for an early-stage product. Its analytic appliance does not yet have an operational counterpart.
- Pricing and pricing model: Pivotal received very low survey scores for value for money and suitability of pricing method, though its new simplified and flexible pricing model should help to improve matters. Pivotal is one of the world's biggest startups, and its revenue will need to grow rapidly to justify EMC's investment.
- Market awareness: The number of inquiries received by Gartner regarding Pivotal products fell to nearly zero after Pivotal was spun off, and has only recently begun to recover. Pivotal's use of the EMC and VMware sales organization is starting to be felt, which is a positive sign.
SAP
Headquartered in Walldorf, Germany, SAP has several DBMS products that are used for transaction systems: SAP Adaptive Server Enterprise (ASE), SAP SQL Anywhere and SAP Hana. Both SAP ASE and SAP SQL Anywhere are available as software only, while SAP Hana is marketed as an appliance.
Strengths
- Leading vision: SAP remains a leader with its vision for HTAP: It now supports most of the SAP applications that run on Hana on a single in-memory database used for transactions and analytics. SAP reports that over 1,000 customers have purchased part or all of SAP Suite on Hana in just over one year of general availability, which underlines the market's interest in HTAP.
- Strong DBMS offerings: SAP has seen strong growth in SAP Hana, SAP ASE (now certified for SAP applications) is growing strongly, and SAP SQL Anywhere continues to lead the mobility market in terms of functionality.
- Performance: Reference customers again identified performance (scalability and reliability) as a major strength for SAP, awarding it one of the highest scores. Additionally, SAP received the highest score for ease of operation across its DBMS products.
Cautions
- Marketing communications: Interactions with users of Gartner's client inquiry service confirm confusion over SAP's messages about how its DBMS products integrate, where each product can be used, what SAP Hana can and cannot do, and most importantly, whether SAP Hana will be required in the future.
- Lack of skills: As inquiries from Gartner clients make clear, skills to support SAP Hana remain scarce in the market.
- HA/DR problems: SAP's reference customers (and especially users of SAP Hana) reported the lowest level of satisfaction with their vendor's HA/DR capabilities. For the second year, SAP also received the lowest score for clients' experience of doing business with it; similarly, in recent Gartner conference surveys,2 SAP received the second-lowest score for ease of doing business.
TmaxData
Headquartered in Bundang-gu, South Korea, TmaxData provides Tibero, an SQL RDBMS featuring various clustering options, integrated encryption and compatibility with other vendors' DBMS products.
Strengths
- Satisfied customers: Reference customers scored TmaxData above average on most satisfaction measures, and substantially above average for ease of implementation.
- Support for mixed workloads: Tibero Active Cluster (TAC) is aimed at transactional workloads using shared disk clustering, while Tibero InfiniData operates in a shared-nothing environment and integrates with Hadoop for analytics workloads.
- Several pricing options: Tibero is available in three editions. Each offers different core/processor pricing options and features.
Cautions
- Limited geographic traction: Despite opening offices in several countries in 2013 and 2014, TmaxData has yet to gain significant traction outside South Korea.
- Uneven postsale support: Reference customers gave TmaxData low scores for support and documentation, and for professional services.
- Software quality: Although no problems were reported consistently, only half of TmaxData's reference customers reported encountering no problems with its products.
VoltDB
Headquartered in Boston, Massachusetts, U.S., VoltDB markets an in-memory row-store operational RDBMS that is increasingly available via vertical-market partners. VoltDB version 4.3, released in May 2014, is an open-source DBMS available as software only.
Strengths
- Technology and vision: Substantial SQL-92 functionality, in-memory DBMS architecture and precompiled Java stored procedures drive VoltDB's high performance in support of HTAP use cases. Tunable consistency and JSON support have been added to give developers more flexibility.
- Customer satisfaction: VoltDB, the only open-source in-memory DBMS vendor, received above-average scores from reference customers for suitability of pricing and professional services.
- Performance and value: As expected for an in-memory DBMS vendor, VoltDB received high scores from reference customers for overall performance of the product and value for the price paid.
Cautions
- Competitive challenges: VoltDB's small, U.S.-centric sales organization and modest ecosystem are growing, but their small size still limits its ability to reach new customers.
- Feature gaps: Although VoltDB customers are overwhelmingly on the newest release, its reference customers identified "some absent or weak functionality."
- Revenue model: VoltDB's revenue remains relatively modest according to Gartner's estimates. Extra funding will be needed to achieve the needed growth. A recent $8 million of Series "B" round venture capital funding should help.
Vendors Added and Dropped
We review and adjust our inclusion criteria for Magic Quadrants and MarketScopes as markets change. As a result of these adjustments, the mix of vendors in any Magic Quadrant or MarketScope may change over time. A vendor's appearance in a Magic Quadrant or MarketScope one year and not the next does not necessarily indicate that we have changed our opinion of that vendor. It may be a reflection of a change in the market and, therefore, changed evaluation criteria, or of a change of focus by that vendor.
Added
- Cloudera: This Hadoop distribution vendor now supports operational transactions through the use of Apache HBase.
- FairCom: This vendor sells a NoSQL DBMS.
- MapR: This Hadoop distribution vendor now supports operational transactions through the use of Apache HBase.
- MariaDB: This vendor offers a MySQL-compatible, open-source RDBMS.
- Neo Technology: This vendor's graph DBMS engine supports transactions.
- Pivotal: This vendor's platform has an in-memory DBMS to support transactions across multiple sources of data.
- TmaxData: This South Korean vendor, which also competes in North America, offers an RDBMS.
Dropped
- Orient Technologies: This vendor failed to meet the inclusion criteria.
Inclusion and Exclusion Criteria
To be included in this Magic Quadrant, vendors and products had to meet the following criteria.
Software availability: Vendors had to have DBMS software generally available for licensing or supported download for at least a year, as of 1 July 2014. Products that have been commercially available for over 10 years but have not grown in terms of revenue at or near the market rate for several years are excluded.
Software releases: We use the most recent generally available release of the software to evaluate current technical capabilities. We do not consider beta, "early access," "technology preview," "ramp up" or other releases that are not generally available. As regards reference customers and their survey responses, all versions currently used in production are considered. When older versions are in use, we consider whether later releases may have addressed any reported issues, but also the rate at which customers move to newer versions.
Feature availability: Product evaluations include technical capabilities, features and functions present in the product or supported for download through midnight, U.S. Eastern Daylight Time on 1 July 2014. Capabilities, product features and functions released after this date could be included at Gartner's discretion and in a manner Gartner that deemed appropriate to ensure the quality of this publication. We also considered how such later releases could affect the end-user experience.
Customers and revenue: Vendors had to generate a minimum of $20 million U.S. dollars in verifiable annual software revenue or have at least 100 verifiable and distinct customer organizations with operational DBMSs in production. In addition, each vendor had to identify a minimum of 10 reference customers who would respond to Gartner's approved reference customer survey (for this year's Magic Quadrant, the survey questionnaire was in English only). Revenue can be from licenses, support and/or maintenance. Gartner may include additional vendors based on undisclosed references in cases of known use for classified but unspecified use cases.
Support: The vendor had to provide support for its operational DBMS product(s). We also considered products that control or participate in the engineering of open-source DBMSs and their support. We required that a DBMS meet Gartner's definition of a DBMS (see Note 1).
Services: Vendors participating in the operational DBMS market had to demonstrate their ability to deliver the necessary services to support transaction systems via the establishment and delivery of support processes, professional services and/or committed resources and budget.
Geographical availability: Vendors had to demonstrate support for operational DBMS customers in at least two of the following major regions: North America, Latin America, Europe, the Middle East and Africa, and Asia/Pacific.
Excluded products: Product categories excluded from this Magic Quadrant (see also Market Definition/Description) are:
- Embedded-only DBMS products
- Data warehouse-only DBMS products
- DBMS products available only as a cloud service
- Prerelational DBMS products
- Graph-only DBMS products
- Data grid products
- Complex-event processing or streaming-data engines
Evaluation Criteria
Ability to Execute
The Ability to Execute criteria are primarily concerned with vendors' capabilities and maturity. Criteria under this heading also consider products' portability, ability to scale, and ability to run in different operating environments (giving the customer a range of options). Ability to Execute criteria are crucial to customers' satisfaction and success with a product, so reference customer interviews and survey responses are weighted heavily throughout.
Product or service includes the technical attributes of the DBMS(s), as well as features and functions built specifically to manage the DBMS when used as a platform for transactions, interactions and observations. We include HA/DR, performance and scalability, support for multiple deployment options (such as virtualization, cloud and hybrid cloud/on-premises), and support for multiple programming languages and new hardware and memory models. These attributes are evaluated across a variety of database sizes and application workloads. We also consider the automated management, tools and resources necessary to manage a database environment, especially as it scales to more complex application workloads. Finally, we consider the flexibility of the DBMS to incorporate new data types, application types and new requirements for distributing data across multiple servers and geographies.
Overall viability includes corporate aspects such as the skills of personnel, financial stability, investment in research and development, and mergers and acquisitions. It also covers the management's ability to respond to market changes and the company's ability to weather market difficulties (crucial for long-term survival). Vendors are further evaluated on their ability to establish dominance in meeting specific market demands.
Sales execution/pricing covers the price/performance and pricing models of the DBMS products, and the ability of the sales force to manage accounts (based on feedback from interviews, surveys and interactions with users of Gartner's client inquiry service). We also consider the market share of the DBMS products. Also considered are the diversity and innovativeness of packaging and pricing models, including the ability to promote, sell and support the products globally.
Market responsiveness/track record includes the diversity of the vendor's offerings in response to changing market demands — for example, its ability and flexibility to offer appliances, cloud deployment, new data types and new programming requirements. We consider general market perceptions of the vendor and its products. We assess both the vendor's ability to adapt to market changes during the previous 18 months and its flexibility in response to market dynamics over a longer period.
Marketing execution evaluates such activities as lead generation, including traditional methods and Internet-enabled trial software delivery, and the execution of channel development through partnering agreements (including coseller, comarketing and colead management arrangements). Also considered are the vendor's coordination and delivery of education and marketing events throughout the world and across vertical markets, and the creation and support of "community" activities that help to raise awareness and develop skills among buyers and prospective customers.
Customer experience evaluations are based primarily on reference customer surveys and interviews conducted for this report, as well as discussions with users of Gartner's inquiry service during the previous six quarters. We consider the vendor's track record of POCs, customers' perceptions of its product(s), and customers' loyalty to the vendor (this reflects their tolerance of its practices and can indicate their level of satisfaction). Additionally, customer input regarding the applicability of products to limited use cases can be significant, depending on the success or failure of the vendor's approach in the market.
Operations covers the alignment of the vendor's organization, as well as whether and how this enhances its ability to deliver. Aspects considered include field delivery of appliances, manufacturing (including the identification of diverse geographic cost advantages), internationalization of the product (in light of both technical and legal requirements) and adequate staffing.
Table 1. Ability to Execute Evaluation Criteria
|
Evaluation Criteria |
Weighting |
|
Product or Service |
High |
|
Overall Viability |
Low |
|
Sales Execution/Pricing |
Medium |
|
Market Responsiveness/Track Record |
High |
|
Marketing Execution |
Medium |
|
Customer Experience |
High |
|
Operations |
Low |
Source: Gartner (October 2014)
Completeness of Vision
Completeness of Vision encompasses a vendor's abilities to understand the functional capabilities needed to support operational environments, to develop a product strategy that meets the market's requirements, to comprehend overall market trends, and to influence or lead the market when necessary. A visionary leadership role is necessary for the long-term viability of both product and company. A vendor's vision may be demonstrated — and improved — by its willingness to extend its influence throughout the market by working with independent third-party application software vendors that deliver both additional functionality for the operational environment and commercial off-the-shelf software. A successful vendor will be able not only to understand the competitive landscape of operational transactions but also to shape the future of this field.
Market understanding assesses a vendor's ability to understand the market and shape its growth and vision. In addition to examining a vendor's core competencies in this market, we considered its awareness of new trends, such as the increasing sophistication of end users, growing scalability needs (especially across server clusters), the cloud as a platform for DBMSs, the demand for in-memory computing and HTAP, use of new consistency models, and the growing desire to use data structures other than relational ones.
Marketing strategy refers to a vendor's marketing themes, research-and-development focus, and ability to choose appropriate target markets and third-party software vendor partnerships to enhance the marketability of its products. For example, we considered whether the vendor encourages and supports ISVs in its efforts to support the DBMS in native mode (via, for instance, comarketing or coadvertising with "value added" partners). This criterion includes the vendor's responses to the market trends identified above and any offers of alternative solutions in its marketing materials and plans.
Sales strategy assesses how a vendor designs and targets its channels and partnerships developed to assist with selling. This is especially important for younger organizations, as a good sales strategy can enable them to greatly increase their market presence, while maintaining lower sales costs (for example, through free downloadable community editions, coselling and joint advertising). This criterion also covers a vendor's strategy for communicating its vision to its field organization and, therefore, to clients and prospective customers. Also included are pricing innovations and strategies, such as new licensing arrangements and cloud-based models for elastic provisioning to support peak demand.
Offering (product) strategy covers the design of product packaging and deployment options, including the availability of cloud versions, developer editions and appliances based on the vendor's DBMS. Vendors should demonstrate a diverse strategy that enables customers to choose what they need to build a complete solution for an operational environment. Also covered are partners' offerings that include technical, marketing, sales and support integration.
Business model covers how a vendor's model of a target market combines with its products and pricing, and whether the vendor can generate profits with this model, judging from its packaging and offerings. Additionally, we consider reviews of publicly announced earnings and forward-looking statements relating to an intended market focus. For private companies and to supplement publicly available information, we use proxies for earnings and new customer growth, such as the number of Gartner clients indicating interest in, or awareness of, a vendor's products during calls to our inquiry service.
Vertical/industry strategy affects a vendor's ability to understand its clients. Aspects such as vertical-market sales teams and partnerships with vertical-market service providers are considered.
Innovation assesses vendors' approach to developing new functionality that aligns with its market and offering strategies by allocating and managing research-and-development spending and leading the market in new directions. Uses of new storage and hardware models are key examples of this.
Geographic strategy, including a vendor's worldwide reach, is assessed by considering its plan to use its own resources in different regions, as well as those of subsidiaries and partners. This criterion considers a vendor's plan for supporting clients throughout the world, around the clock, and in many languages. Anticipation of regional and global economic conditions is also considered.
Table 2. Completeness of Vision Evaluation Criteria
|
Evaluation Criteria |
Weighting |
|
Market Understanding |
High |
|
Marketing Strategy |
Medium |
|
Sales Strategy |
Medium |
|
Offering (Product) Strategy |
High |
|
Business Model |
Low |
|
Vertical/Industry Strategy |
Medium |
|
Innovation |
High |
|
Geographic Strategy |
Low |
Source: Gartner (October 2014)
Quadrant Descriptions
Leaders
Leaders generally demonstrate the most support for a broad range of operational applications, based on support for a wide range of data types and large numbers of concurrent users. These vendors demonstrate consistent customer satisfaction and strong customer support. Many have competed in this market for many years, and have built a wide partner ecosystem for their products. Hence, Leaders generally represent the lowest risk for customers in the areas of performance, scalability, reliability and support. As the market's demands change, so Leaders demonstrate strong vision in support not only of the market's current needs but also of emerging trends. Finally, the messaging, product research and development, and delivery of leaders are in line with today's market and with new trends in both DBMS software and hardware technology.
Challengers
Challengers are stable vendors with strong, established offerings but a relative lack of vision. It is normal for some vendors to have high scores for execution but to lag in terms of the adoption levels and vision needed for leadership. Challengers normally show strong corporate viability and financial stability, and demonstrate strong customer support. However, they lack the vision to support some of the new trends in the operational DBMS market, such as support for interaction and observation data in transactions, or a road map for moving toward in-memory DBMS capabilities. Although they may be lacking in relation to some of the market's innovative concepts, Challengers offer stability, simplicity of installation and support, and strong performance. As with the Niche Players, Gartner considers support of a limited number of data types and hardware models as evidence of limited vision.
Visionaries
Visionaries take a forward-thinking approach to managing the hardware, software and end-user aspects of an operational DBMS environment. Visionaries typically have innovative ideas for new functionality and advanced use of new hardware. They have the requisite number of production customers, but lack the market momentum of Leaders. In this market, Niche Players are often young, small and innovative vendors with great new ideas that are spurring on the more mature vendors and the market in general.
Niche Players
Niche Players generally deliver a highly specialized product with limited market appeal. Frequently, a Niche Player provides an exceptional operational DBMS product, but is isolated or limited to a specific end-user community, region or industry. Although the solution itself may not have limitations, adoption is limited. Niche Players contains vendors from several categories:
- Those with an operational DBMS product that lacks a strong or a large customer base
- Those with an operational DBMS that lacks the breadth of functionality of those of Leaders
- Those with new operational DBMS products that lack general customer acceptance or the proven functionality to move beyond niche status
Niche Players typically offer smaller, specialized solutions that are used for specific operational and transactional applications, depending on the client's needs.
Context
At one time, Gartner viewed the online transaction processing (OLTP) DBMS market as very mature, with few new entrants to challenge the status quo. However, in recent years, the market has changed rapidly, which prompted our redefinition of it in 2013 as the operational DBMS market (see "The OLTP DBMS Market Becomes the Operational DBMS Market"). With the introduction of NoSQL and Hadoop in support of unstructured data in transactions and the viable use of in-memory computing, many organizations are beginning to use these new DBMS engines for specific use cases, such as global scalability of Web applications.
As there are now many new entrants, including small and less mature vendors, the market appears to be split in two, although compared with the situation in 2013, the space between its two groups has reduced. In one group are the innovative new vendors. In the other are the traditional, strong, mature leaders. The reason for most of the vendors being below the midline in the Magic Quadrant is that they support only one or two of the DBMS models (which include key value, graph, relational, table-style and document-style), and only one or two of the multiple data types (such as structured [relational], unstructured, XML, interaction and observation). The Leaders support a wide range of models and data types in a scalable, highly available environment, which is one reason for the considerable space between several of them and the newer vendors.
Another major focus for vendors in this market is support for in-memory computing. Most vendors are beginning to add this functionality to their DBMSs, some with an in-memory-only model. Due to its inherent speed, in-memory computing is becoming necessary for the processing of interaction and observation data integrated into transactions. Most of the traditional vendors have introduced an in-memory DBMS, generally in support of analytics. This will eventually become the preferred model for all DBMSs. The one form of memory not well adapted to data is flash when used as addressable memory and not as a form of fast disk replacement. NAND flash is slower than DRAM, but it is more efficient when used as addressable memory than as a disk block cache.
As the new vendors mature and offer a wider range of functions, the operational DBMS market will become more homogeneous and commoditized (see "IT Market Clock for Database Management Systems, 2014").
This Magic Quadrant deals with the key information management capabilities for transaction processing. It should therefore interest anyone involved in defining, purchasing, building or managing a transaction-processing environment — notably, CIOs, CTOs, infrastructure managers, database and application architects, database administrators and IT purchasing managers.
For this Magic Quadrant, we based our analysis on information gathered from interactions with Gartner clients over the past 12 months and our survey of the vendors' reference customers, performed during July and August 2014.3 We also considered earlier information and any news about vendors' products, customers and finances that arose during the analysis time frame.
Market Overview
The OLTP DBMS market, from which the operational DBMS market evolved, was very mature in the early years of the 21st century. However, as Internet usage and availability grew, so did the applications necessary to support the associated, growing infrastructure. Consequently, over the past five years, many new vendors have entered this market with products to support the specialized applications required by a new and global business arena.
Many drivers of innovation are widely accepted. New forms of data — that were previously difficult or impossible to capture — have become available from connected devices (the Internet of Things), such as smart meter data and machine or device data; we call this "observation data." The pervasive use of personal devices and social media has also become a source of social- and business-related data; we call this "interaction data." These new forms of data must now be used not only for analytics, but also within transactions. Data from vendors' reference customers confirms this change, as 75% of the respondents to our survey use interaction data in transactions, and over 50% use observation data in transaction processing.3
In terms of hardware, new devices, servers, and networking, memory and storage options (to name but a few) have proliferated. These both enable and require new ways to process the data they create or support. For in-memory DBMSs, the amount of memory available on individual servers is already reaching 32TB to 64TB. Organizations need to capture both structured and unstructured data for use in transactions. Furthermore, they must use the data from transactions, observations and interactions in real time for decision processing as part of, not separately from, the transactions. This process is the definition of HTAP (for further details, see "Hype Cycle for In-Memory Computing, 2014").
To support the new operational DBMS market, many new vendors have emerged with innovative DBMS engines that support transactions on a global scale, real-time transactions integrated with analytics, streaming data transactions, and more. These new vendors are single-minded in terms of direction. Once their ideas are proven, more mature vendors will feel obliged to adopt some of this technology.
The new vendors' activities include the use of JSON for data structures in applications; new and less restrictive forms of consistency (allowing for eventual consistency); larger amounts of DRAM for in-memory DBMSs; and new file structures that differ from relational ones, such as those for key-value and document-store file systems. Many of these vendors support these NoSQL systems for simplicity, agile development, support of unstructured data types, scalability and performance. Already, an increasing number of mature DBMS vendors are adopting these technologies in their systems.
Although we exclude cloud-only delivery from this Magic Quadrant, the cloud is being widely adopted as a delivery platform in the operational DBMS market. Over the next few years, we expect most vendors to offer cloud versions of their DBMS products. These will range from simple offerings of support for infrastructure as a service and cloud hosting, to full cloud DBMS platforms with elasticity and multitenant capabilities. As the operational DBMS market matures, cloud deployment — and especially hybrid deployment — will become a criterion of importance as it offers users an additional platform choice.
출처 : http://www.gartner.com/technology/reprints.do?id=1-23A415Q&ct=141020&st=sb
IT News 2014. 6. 13. 13:52
AWS를 이용하여 RDB 서비스를 지원하기 위한 User Guide.
이외에도 Bigdata를 위한 NoSQL 서비스를 지원하기 위한 User Guide도 있으나, 일단 Pass~~
AWS에서 White Paper를 찾으면 아래와 같이 다양한 Guide 문서를 찾을 수 있네요.
Amazon Relational Database Service User Guide .pdf
IT News 2014. 6. 13. 13:44
Remote Collaboration Survey Report ASIA
Remote Collaboration을 진행하는데 있어서 제약과 한계를 극복하는 방법에 대한 내용.
Remote_Collaboration_Survey_Report_ASIA.PDF
출처는 첨부파일 내부에... ^^
IT News 2014. 2. 6. 17:49

Most Popular Programming Languages of 2014
February 3, 2014
Every year we release data on the "Most Popular Programming Languages" based on thousands of data points we've collected by processing over 100,000+ coding tests and challenges by over 2,000+ employers.
This gives us a pretty good idea on what the trends are for the upcoming year in terms of what companies are looking for. It's data we hope will be especially helpful for new computer sciences graduates or coders looking to stay ahead of the curve.
For the third year in a row, Python retains it's #1 dominance followed by Java, C++, and Javascript.
This year's most noticeable changes were a 300% increase in Objective-C submissions, a 100% surge in C#, as well as a 33% increase in Javascript submissions while PHP lost -55%, Perl dropped -16%, and Java shrank -14%.

Another major index to look at is from TIBOE which is a more accurate measure of language market share compared to the CodeEval index which is a much better indicator for language popularity in industry.
This of course shouldn't be the only consideration used in choosing a programming language. Read this recent write up from our friends at CodingforInterviews.com for some more insights.
About CodeEval
CodeEval is an exclusive community of over 24,000+ competitive developers. Members can compete with each other, challenge their friends and build out their profiles to showcase their coding skills. Get started on your first coding challenge here (there are over 129!)
For companies, over 2,000+ employers have company profiles and screen candidates on the CodeEval platform. Join today and create a FREE company profile!
@codeeval #programming2014
- See more at: http://blog.codeeval.com/2014?python#.UvNLSZ2wfs2
IT News 2014. 1. 10. 14:13
Boon JSON parser seems to be the fastestI'll publish object serialization numbers later. Last I checked it was quite a bit faster than the rest.Here are some benchmark numbers parsing various sample JSON files from json.org and a sample that a user of Boon JSON sent in.
To go from a 2K JSON String to a Map, Boon is 2x or so faster. Yes you say, but how is Boon at larger files?
The above graph shows Boon, GSON and Jackson parsing a 1.7 MB string. Boon is up to twice as fast.
Yes you say, but how does boon do at parsing byte[], reader, inputStream, etc.? Pretty much Boon wins in every category for all files that I have tested, which were quite a few.
It took a bit of doing. Boon has an I/O lib which I employed to speed up the inputStream and reader support. Boon also has a relaxed mode JSON parser that allows no-quotes etc., it is just as fast as the strict parser.
The above is not a complete list of tests.
Here are some numbers to go with the graphs.
12/25/13 1.7 MB JSON String
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.s.BoonBenchmark.citmCatalog thrpt 8 5 1 873.970 94.240 ops/s
i.g.j.s.GSONBenchmark.citmCatalog thrpt 8 5 1 410.783 217.476 ops/s
i.g.j.s.JacksonASTBenchmark.citmCatalog thrpt 8 5 1 294.690 47.593 ops/s
i.g.j.s.JacksonObjectBenchmark.citmCatalog thrpt 8 5 1 305.787 29.107 ops/s
i.g.j.s.JsonSmartBenchmark.citmCatalog thrpt 8 5 1 311.063 29.646 ops/s
2K JSON String
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.s.BoonBenchmark.medium thrpt 8 5 1 816416.973 13231.453 ops/s
i.g.j.s.GSONBenchmark.medium thrpt 8 5 1 341148.250 18117.075 ops/s
i.g.j.s.JacksonASTBenchmark.medium thrpt 8 5 1 263167.610 147495.795 ops/s
i.g.j.s.JacksonObjectBenchmark.medium thrpt 8 5 1 282024.617 6922.138 ops/s
i.g.j.s.JsonSmartBenchmark.medium thrpt 8 5 1 296944.993 7852.929 ops/s
1.7 MB JSON byte[]
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.b.BoonBenchmark.citmCatalog thrpt 8 5 1 628.710 91.286 ops/s
i.g.j.b.GSONBenchmark.citmCatalog thrpt 8 5 1 439.203 120.003 ops/s
i.g.j.b.JacksonASTBenchmark.citmCatalog thrpt 8 5 1 381.350 97.841 ops/s
i.g.j.b.JacksonObjectBenchmark.citmCatalog thrpt 8 5 1 402.537 3.634 ops/s
i.g.j.b.JsonSmartBenchmark.citmCatalog thrpt 8 5 1 341.940 18.847 ops/s
2K JSON byte[]
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.b.BoonBenchmark.medium thrpt 8 5 1 648162.887 18697.319 ops/s
i.g.j.b.GSONBenchmark.medium thrpt 8 5 1 260145.827 5934.588 ops/s
i.g.j.b.JacksonASTBenchmark.medium thrpt 8 5 1 289863.140 48969.875 ops/s
i.g.j.b.JacksonObjectBenchmark.medium thrpt 8 5 1 289010.543 11205.881 ops/s
i.g.j.b.JsonSmartBenchmark.medium thrpt 8 5 1 262873.957 3901.193 ops/s
1.7 MB JSON Inputstream
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.inputStream.BoonBenchmark.citmCatalog thrpt 8 5 1 626.907 31.450 ops/s
i.g.j.inputStream.GSONBenchmark.citmCatalog thrpt 8 5 1 426.120 13.946 ops/s
i.g.j.inputStream.JacksonASTBenchmark.citmCatalog thrpt 8 5 1 376.820 115.502 ops/s
i.g.j.inputStream.JacksonObjectBenchmark.citmCatalog thrpt 8 5 1 360.850 89.648 ops/s
2K file JSON Inputstream
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.inputStream.BoonBenchmark.medium thrpt 8 5 1 218730.830 5262.596 ops/s
i.g.j.inputStream.GSONBenchmark.medium thrpt 8 5 1 151255.407 4486.414 ops/s
i.g.j.inputStream.JacksonASTBenchmark.medium thrpt 8 5 1 156512.527 107512.401 ops/s
i.g.j.inputStream.JacksonObjectBenchmark.medium thrpt 8 5 1 160793.407 4056.790 ops/s
1.7 MB JSON Reader
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.r.BoonBenchmark.citmCatalog thrpt 8 5 1 615.313 63.716 ops/s
i.g.j.r.GSONBenchmark.citmCatalog thrpt 8 5 1 411.847 18.978 ops/s
i.g.j.r.JacksonASTBenchmark.citmCatalog thrpt 8 5 1 264.727 118.541 ops/s
i.g.j.r.JacksonObjectBenchmark.citmCatalog thrpt 8 5 1 246.783 93.409 ops/s
i.g.j.r.JsonSmartBenchmark.citmCatalog thrpt 8 5 1 151.097 3.502 ops/s
2k JSON Reader
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.r.BoonBenchmark.medium thrpt 8 5 1 185075.093 6528.567 ops/s
i.g.j.r.GSONBenchmark.medium thrpt 8 5 1 134025.760 3385.134 ops/s
i.g.j.r.JacksonASTBenchmark.medium thrpt 8 5 1 107676.323 60674.421 ops/s
i.g.j.r.JacksonObjectBenchmark.medium thrpt 8 5 1 116903.500 3206.994 ops/s
i.g.j.r.JsonSmartBenchmark.medium thrpt 8 5 1 77898.710 2434.773 ops/s
Other JSON.org examples: webxml json.org example
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.s.BoonBenchmark.webxml thrpt 8 5 1 421016.033 13428.790 ops/s
i.g.j.s.GSONBenchmark.webxml thrpt 8 5 1 143801.263 7870.384 ops/s
i.g.j.s.JacksonASTBenchmark.webxml thrpt 8 5 1 125981.563 36753.717 ops/s
i.g.j.s.JacksonObjectBenchmark.webxml thrpt 8 5 1 130069.577 25055.300 ops/s
i.g.j.s.JsonSmartBenchmark.webxml thrpt 8 5 1 132422.153 10254.167 ops/s
Boon 3X faster sgml json.org example
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.s.BoonBenchmark.sgml thrpt 8 5 1 1846015.410 101291.991 ops/s
i.g.j.s.GSONBenchmark.sgml thrpt 8 5 1 988186.433 35337.393 ops/s
i.g.j.s.JacksonASTBenchmark.sgml thrpt 8 5 1 680502.597 289591.197 ops/s
i.g.j.s.JacksonObjectBenchmark.sgml thrpt 8 5 1 709969.980 29621.959 ops/s
i.g.j.s.JsonSmartBenchmark.sgml thrpt 8 5 1 796387.753 22697.397 ops/s
Boon 2x faster actionLabel json.org example
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.s.BoonBenchmark.actionLabel thrpt 8 5 1 1109285.703 78440.576 ops/s
i.g.j.s.GSONBenchmark.actionLabel thrpt 8 5 1 429742.283 10097.416 ops/s
i.g.j.s.JacksonASTBenchmark.actionLabel thrpt 8 5 1 421132.630 10514.598 ops/s
i.g.j.s.JacksonObjectBenchmark.actionLabel thrpt 8 5 1 403535.453 16382.734 ops/s
i.g.j.s.JsonSmartBenchmark.actionLabel thrpt 8 5 1 453847.673 25607.331 ops/s
Boon over 2x faster menu json.org example
Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.s.BoonBenchmark.menu thrpt 8 5 1 2582429.350 700873.986 ops/s
i.g.j.s.GSONBenchmark.menu thrpt 8 5 1 1240234.083 22312.822 ops/s
i.g.j.s.JacksonASTBenchmark.menu thrpt 8 5 1 1242132.793 19273.775 ops/s
i.g.j.s.JacksonObjectBenchmark.menu thrpt 8 5 1 1141071.207 36489.605 ops/s
i.g.j.s.JsonSmartBenchmark.menu thrpt 8 5 1 1463778.480 57490.408 ops/s
Boon 2x faster. Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.s.BoonBenchmark.widget thrpt 8 5 1 1485476.970 79222.003 ops/s
i.g.j.s.GSONBenchmark.widget thrpt 8 5 1 810153.490 20079.953 ops/s
i.g.j.s.JacksonASTBenchmark.widget thrpt 8 5 1 724349.650 284735.196 ops/s
i.g.j.s.JacksonObjectBenchmark.widget thrpt 8 5 1 705271.907 42304.730 ops/s
i.g.j.s.JsonSmartBenchmark.widget thrpt 8 5 1 728506.560 29680.028 ops/s
Boon is damn fast. It has many modes to fit various mediums depending on your goals (small footprint, direct byte parse, etc.). Don't worry, boon is not hard to use. It just works. Benchmark Mode Thr Count Sec Mean Mean error Units
i.g.j.b.BoonAsciiBytes.actionLabel thrpt 8 5 1 302902.677 21981.467 ops/s
i.g.j.b.BoonAsciiBytes.citmCatalog thrpt 8 5 1 628.150 26.607 ops/s
i.g.j.b.BoonAsciiBytes.medium thrpt 8 5 1 320658.760 38751.800 ops/s
i.g.j.b.BoonAsciiBytes.menu thrpt 8 5 1 2081501.213 113660.611 ops/s
i.g.j.b.BoonAsciiBytes.sgml thrpt 8 5 1 998463.200 31916.216 ops/s
i.g.j.b.BoonAsciiBytes.small thrpt 8 5 1 11095898.987 534428.831 ops/s
i.g.j.b.BoonAsciiBytes.webxml thrpt 8 5 1 148348.463 5512.808 ops/s
i.g.j.b.BoonAsciiBytes.widget thrpt 8 5 1 879580.747 14598.011 ops/s
i.g.j.b.BoonBenchMarkLax.actionLabel thrpt 8 5 1 806689.270 28745.917 ops/s
i.g.j.b.BoonBenchMarkLax.citmCatalog thrpt 8 5 1 633.087 77.455 ops/s
i.g.j.b.BoonBenchMarkLax.medium thrpt 8 5 1 569042.093 61404.916 ops/s
i.g.j.b.BoonBenchMarkLax.menu thrpt 8 5 1 2600248.763 105320.234 ops/s
i.g.j.b.BoonBenchMarkLax.sgml thrpt 8 5 1 1476412.973 284184.058 ops/s
i.g.j.b.BoonBenchMarkLax.small thrpt 8 5 1 13336195.790 1442531.930 ops/s
i.g.j.b.BoonBenchMarkLax.webxml thrpt 8 5 1 270060.157 6539.573 ops/s
i.g.j.b.BoonBenchMarkLax.widget thrpt 8 5 1 1262768.937 51676.215 ops/s
i.g.j.b.BoonBenchMarkUTF8Bytes.actionLabel thrpt 8 5 1 185209.077 670100.163 ops/s
i.g.j.b.BoonBenchMarkUTF8Bytes.citmCatalog thrpt 8 5 1 379.917 30.037 ops/s
i.g.j.b.BoonBenchMarkUTF8Bytes.medium thrpt 8 5 1 217107.220 5247.417 ops/s
i.g.j.b.BoonBenchMarkUTF8Bytes.menu thrpt 8 5 1 1319969.417 79745.189 ops/s
i.g.j.b.BoonBenchMarkUTF8Bytes.sgml thrpt 8 5 1 688184.650 34033.100 ops/s
i.g.j.b.BoonBenchMarkUTF8Bytes.small thrpt 8 5 1 7486431.520 1228519.698 ops/s
i.g.j.b.BoonBenchMarkUTF8Bytes.webxml thrpt 8 5 1 104078.393 15332.908 ops/s
i.g.j.b.BoonBenchMarkUTF8Bytes.widget thrpt 8 5 1 526663.853 214399.644 ops/s
i.g.j.b.BoonCharArray.actionLabel thrpt 8 5 1 407056.423 149970.346 ops/s
i.g.j.b.BoonCharArray.citmCatalog thrpt 8 5 1 391.130 55.374 ops/s
i.g.j.b.BoonCharArray.medium thrpt 8 5 1 320601.040 83669.815 ops/s
i.g.j.b.BoonCharArray.menu thrpt 8 5 1 1686792.320 112046.346 ops/s
i.g.j.b.BoonCharArray.sgml thrpt 8 5 1 1052574.220 44541.919 ops/s
i.g.j.b.BoonCharArray.small thrpt 8 5 1 8071292.173 663678.327 ops/s
i.g.j.b.BoonCharArray.webxml thrpt 8 5 1 181207.910 32126.919 ops/s
i.g.j.b.BoonCharArray.widget thrpt 8 5 1 878541.030 137067.187 ops/s
i.g.j.b.BoonFastParser.actionLabel thrpt 8 5 1 601141.330 77361.337 ops/s
i.g.j.b.BoonFastParser.citmCatalog thrpt 8 5 1 429.987 198.559 ops/s
i.g.j.b.BoonFastParser.medium thrpt 8 5 1 462712.293 118751.410 ops/s
i.g.j.b.BoonFastParser.menu thrpt 8 5 1 1981728.817 239514.140 ops/s
i.g.j.b.BoonFastParser.sgml thrpt 8 5 1 1117030.450 209863.168 ops/s
i.g.j.b.BoonFastParser.small thrpt 8 5 1 10197156.600 169372.770 ops/s
i.g.j.b.BoonFastParser.webxml thrpt 8 5 1 230100.983 62048.894 ops/s
i.g.j.b.BoonFastParser.widget thrpt 8 5 1 1242538.033 169654.975 ops/s
i.g.j.b.BoonStringDirect.actionLabel thrpt 8 5 1 461358.763 45184.611 ops/s
i.g.j.b.BoonStringDirect.citmCatalog thrpt 8 5 1 332.883 25.544 ops/s
i.g.j.b.BoonStringDirect.medium thrpt 8 5 1 323354.063 18819.168 ops/s
i.g.j.b.BoonStringDirect.menu thrpt 8 5 1 1668149.967 52797.831 ops/s
i.g.j.b.BoonStringDirect.sgml thrpt 8 5 1 933777.700 77093.442 ops/s
i.g.j.b.BoonStringDirect.small thrpt 8 5 1 7111685.283 205942.968 ops/s
i.g.j.b.BoonStringDirect.webxml thrpt 8 5 1 154376.677 50416.916 ops/s
i.g.j.b.BoonStringDirect.widget thrpt 8 5 1 575450.757 45103.058 ops/s
출처 : http://rick-hightower.blogspot.kr/2013/12/boon-json-parser-seems-to-be-fastest.html
|